ПРИЛОЖЕНИЕ
СЪДЪРЖАНИЕ
|
ГЛАВА 1: |
Обмен на ДНК данни |
|
1. |
Свързани с ДНК криминалистични въпроси, правила и алгоритми за сравняване |
|
1.1. |
Свойства на ДНК профилите |
|
1.2. |
Правила за сравняване |
|
1.3. |
Правила за съобщаване на резултатите |
|
2. |
Таблица на кодовите номера на държавите-членки |
|
3. |
Функционален анализ |
|
3.1. |
Наличност на системата |
|
3.2. |
Втори етап |
|
4. |
Документ за контрол на интерфейса при обмен на ДНК данни |
|
4.1. |
Въведение |
|
4.2. |
Дефиниране на XML-структурата |
|
5. |
Архитектура на приложението, сигурността и комуникациите |
|
5.1. |
Обзорен преглед |
|
5.2. |
Архитектура на горното ниво |
|
5.3. |
Стандарти за сигурност и защита на данните |
|
5.4. |
Протоколи и стандарти, които да се използват за механизма за криптиране sMIME и свързани пакети |
|
5.5. |
Архитектура на приложението |
|
5.6. |
Протоколи и стандарти, които да се използват за архитектурата на приложението |
|
5.7. |
Комуникационна среда |
|
ГЛАВА 2: |
Обмен на дактилоскопични данни (документ за контрол на интерфейса) |
|
1. |
Обзор на съдържанието на файловете |
|
2. |
Формат на записите |
|
3. |
Логически запис тип-1: заглавна част на файла |
|
4. |
Логически запис тип-2: описателен текст |
|
5. |
Логически запис тип-4: изображение с висока резолюция в сивата скала |
|
6. |
Логически запис тип-9: запис на признаци (minutiae) |
|
7. |
Запис тип-13 на изображение на следи с променлива резолюция |
|
8. |
Запис тип-15 на изображение на отпечатък от длан с променлива резолюция |
|
9. |
Допълнения към глава 2 (обмен на дактилоскопични данни) |
|
9.1. |
ASCII разделителни кодове |
|
9.2. |
Изчисляване на буквено-цифровия контролен символ |
|
9.3. |
Символни кодове |
|
9.4. |
Кратко описание на транзакция |
|
9.5. |
Дефиниции на запис тип-1 |
|
9.6. |
Дефиниции на запис тип-2 |
|
9.7. |
Кодове за компресия в сивата скала |
|
9.8. |
Спецификация на съобщенията |
|
ГЛАВА 3: |
Обмен на данни за регистрацията на превозни средства |
|
1. |
Общ набор от данни за автоматизирано търсене на данни за регистрацията на превозни средства |
|
1.1. |
Определения |
|
1.2. |
Търсене на превозно средство/собственик/ползвател |
|
2. |
Сигурност на данните |
|
2.1. |
Обзорен преглед |
|
2.2. |
Характеристики на сигурността, свързани с обмена на съобщения |
|
2.3. |
Характеристики на сигурността, несвързани с обмена на съобщения |
|
3. |
Технически условия на обмена на данните |
|
3.1. |
Общо описание на приложението EUCARIS |
|
3.2. |
Функционални и нефункционални изисквания |
|
ГЛАВА 4: |
Оценяване |
|
1. |
Процедура за оценяване съгласно член 20 (подготовка на решения в съответствие с член 25, параграф 2 от Решение 2008/615/ПВР) |
|
1.1. |
Въпросник |
|
1.2. |
Пилотно изпитване |
|
1.3. |
Посещение за оценка |
|
1.4. |
Докладване на Съвета |
|
2. |
Процедура за оценяване съгласно член 21 |
|
2.1. |
Статистика и доклад |
|
2.2. |
Преразглеждане |
|
3. |
Експертни заседания |
ГЛАВА 1: Обмен на ДНК данни
1. Свързани с ДНК криминалистични въпроси, правила и алгоритми за сравняване
1.1. Свойства на ДНК профилите
ДНК профилът може да съдържа 24 двойки числа, представляващи алелите на 24-те локуса, които също се използват в ДНК процедурите на Интерпол. Наименованията на тези локуси са показани в следната таблица:
|
VWA |
TH01 |
D21S11 |
FGA |
D8S1179 |
D3S1358 |
D18S51 |
Amelogenin |
|
TPOX |
CSF1P0 |
D13S317 |
D7S820 |
D5S818 |
D16S539 |
D2S1338 |
D19S433 |
|
Penta D |
Penta E |
FES |
F13A1 |
F13B |
SE33 |
CD4 |
GABA |
Седемте отбелязани в сиво локуса на най-горния ред представляват както настоящия европейски стандартен набор от локуси (ESS), така и стандартния набор на Интерпол от локуси (ISSOL).
Правила за включване:
ДНК профилите, до които държавите-членки предоставят достъп с цел търсене и сравняване, както и ДНК профилите, изпращани с цел търсене и сравняване, трябва да съдържат поне 6 изцяло обозначени (1) локуса, като могат да съдържат допълнителни локуси или непопълнени такива в зависимост от наличността им. Референтните ДНК профили трябва да съдържат поне 6 от седемте локуса на ESS. За да се повиши точността на съвпаденията, всички налични алели се съхраняват в индексираната база данни с ДНК профили и се използват за търсене и сравняване. Всяка държава-членка следва да приложи в най-краткия практически възможен срок всеки нов вариант на ESS от локуси, приет от ЕС.
Не се допускат смесени профили, така че алелните стойности на всеки локус ще се състоят само от 2 цифри, които могат да бъдат еднакви при наличие на хомозиготност в даден локус.
При заявка за търсене с неизвестна стойност „жокер“ („wild-cards“) или с микроварианти се спазват следните правила:
|
— |
всички нецифрови стойности, с изключение на амелогенина, съдържащи се в профила (напр. „o“, „f“, „r“, „na“, „nr“ или „un“), се превръщат автоматично при експортирането в „жокер“ (*) и се извършва пълно търсене, |
|
— |
цифровите стойности 0, 1 или 99, съдържащи се в профила, се превръщат автоматично при експортирането в „жокер“ (*) и се извършва пълно търсене, |
|
— |
ако за един локус са подадени 3 алела, приема се първият алел, а останалите 2 алела се превръщат автоматично при експортирането в „жокер“ (*) и се извършва пълно търсене, |
|
— |
когато за алел 1 или 2 е подадена стойност „жокер“ (*), се търсят и двете пермутации на цифровата стойност за локуса (напр. 12, * може да съответства на 12,14 или на 9,12), |
|
— |
микровариантите на пентануклеотид (Penta D, Penta E и CD4) се сравняват по следния начин:
|
|
— |
микровариантите на тетрануклеотид (останалите локуси са тетрануклеотиди) се сравняват по следния начин:
|
1.2. Правила за сравняване
Сравняването на 2 ДНК профила се извършва въз основа на локусите, за които и в двата ДНК профила е налице една и съща алелна двойка. В двата ДНК профила трябва да има съвпадение на поне 6 изцяло обозначени локуса (без амелогенин), преди да се изпрати отговор за наличие на съвпадение.
Пълно съвпадение (качество 1) се определя като съвпадение, когато са еднакви всички алелни стойности на сравняваните локуси, обикновено съдържащи се в искането и отговора на справка за ДНК профили. Близко съвпадение се определя като съвпадение, при което е налице различна стойност само за една от всичките сравнявани алели в двата ДНК профила (качества 2, 3 и 4). Приема се, че има близко съвпадение, само ако в двата сравнявани ДНК профила е налице съвпадение на поне 6 изцяло обозначени локуса.
Причините за близко съвпадение могат да бъдат следните:
|
— |
печатна грешка, допусната при ръчно въвеждане на данните за един от ДНК профилите в искането за справка или в ДНК базата данни, |
|
— |
грешка при определянето или „извикването“ на алели в хода на процедурата за генериране на ДНК профила. |
1.3. Правила за съобщаване на резултатите
Съобщават се както пълните, така и близките съвпадения и липсата на съвпадение.
Съобщението за резултатите се изпраща на националната точка за контакт, отправила искането, като се предоставя на разположение и на националната точка за контакт, до която е отправено искането (за да може тя да прецени естеството и броя на евентуалните следващи искания за допълнителни налични лични данни и друга информация, която е свързана с ДНК профила, съответстващ на съвпадението в съответствие с членове 5 и 10 от Решение 2008/615/ПВР).
2. Таблица на кодовите номера на държавите-членки
В съответствие с Решение 2008/615/ПВР за определяне на наименованията на домейни, както и за другите конфигуративни параметри, които се изискват от приложенията за обмен на ДНК данни по защитени мрежи съгласно договореностите от Прюм, се използва кодиране по стандарта ISO 3166-1 alpha-2.
Кодовете по ISO 3166-1 alpha-2 са следните двубуквени кодове за държавите-членки.
|
Имена на държавите-членки |
Код |
Имена на държавите-членки |
Код |
|
Белгия |
BE |
Люксембург |
LU |
|
България |
BG |
Унгария |
HU |
|
Чешката република |
CZ |
Малта |
MT |
|
Дания |
DK |
Нидерландия |
NL |
|
Германия |
DE |
Австрия |
AT |
|
Естония |
EE |
Полша |
PL |
|
Гърция |
EL |
Португалия |
PT |
|
Испания |
ES |
Румъния |
RO |
|
Франция |
FR |
Словакия |
SK |
|
Ирландия |
IE |
Словения |
SI |
|
Италия |
IT |
Финландия |
FI |
|
Кипър |
CY |
Швеция |
SE |
|
Латвия |
LV |
Обединеното кралство |
UK |
|
Литва |
LT |
|
|
3. Функционален анализ
3.1. Наличност на системата
Исканията по член 3 от Решение 2008/615/ПВР следва да пристигат в съответната база данни по хронологичен ред съгласно реда им на изпращане, а отговорите следва да се изпращат така че да пристигат в поискалата ги държава-членка в 15-минутен срок от пристигането на искането.
3.2. Втори етап
Когато държава-членка получи съобщение за съвпадение, нейната национална точка за контакт отговаря за сравняването на стойностите на профила, предаден като запитване, и стойностите на профила(ите), получени като отговор, за да валидира и провери доказателствената стойност на профила. Националните точки за контакт могат да осъществяват пряк контакт помежду си с цел валидиране.
Процедурите за правна помощ започват след валидирането на съществуващо съвпадение между два профила, въз основа на получените по време на фазата за автоматизирано консултиране съобщения за „пълно съвпадение“ и „близко съвпадение“.
4. Документ за контрол на интерфейса при обмен на ДНК данни
4.1. Въведение
4.1.1.
В тази глава се определят изискванията за обмена на информация за ДНК профили между системите от ДНК бази данни на всички държави-членки. Полетата в заглавната част са дефинирани специално за целите на обмена на ДНК данни по линия на Прюм, а съдържащата данните част е разработена на базата на частта за данните за ДНК профили в XML-схемата, дефинирана за електронния портал на Интерпол за обмен на ДНК данни.
Данните се обменят чрез SMTP (Simple Mail Transfer Protocol) и други модерни технологии, като се използва сървър за централизирано предаване на съобщенията, предоставен от доставчика на мрежови услуги. XML-файлът се транспортира в съдържателната част на съобщението.
4.1.2.
Този ICD определя само съдържанието на съобщението. Всички специфични за мрежата и съобщението въпроси, се дефинират еднообразно, за да се осигури обща техническа база за обмен на ДНК данни.
Това включва:
|
— |
формáта на полето „предмет“ на съобщението, за да може да се осъществи автоматизираната обработка на съобщенията, |
|
— |
дали е необходимо да се криптира съдържанието и ако е така, кои методи следва да се изберат, |
|
— |
максималната дължина на съобщението. |
4.1.3.
Съобщението във XML-формат е структурирано в:
|
— |
заглавна част, в която се съдържа информация относно параметрите на предаване и |
|
— |
част за данните, в която се съдържа специфична информация за профила, както и самият профил. |
За исканията и за отговорите се използва една и съща XML-схема.
За да могат да се правят изчерпателни проверки на неидентифицирани ДНК профили (член 4 от Решение 2008/615/ПВР), е възможно да се изпращат по няколко профила в едно съобщение. Максималният брой на профилите в едно съобщение трябва да бъде определен. Броят им зависи от максималния допустим размер на съобщенията и се определя след избора на пощенски сървър.
XML пример:
<?version="1.0" standalone="yes"?>
<PRUEMDNAx xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<header>
(…)
</header>
<datas>
(…)
</datas>
[<datas> структурата на данните се повтаря, когато се изпращат повече профили (….) в едно SMTP-съобщение, разрешено само за случаите по член 4
</datas>]
</PRUEMDNA>
4.2. Дефиниране на XML-структурата
Следните дефиниции са само за целите на документирането и по-добрата четивност, а информацията със задължителен характер се дава във файла с XML-схема (PRUEM DNA.xsd).
4.2.1.
Тази схема съдържа следните полета:
|
Fields |
Type |
Description |
|
header |
PRUEM_header |
Occurs: 1 |
|
datas |
PRUEM_datas |
Occurs: 1 … 500 |
4.2.2.
|
4.2.2.1. |
Заглавна част PRUEM (PRUEM header) Тази структура описва заглавната част на XML-файла. Тя съдържа следните полета:
|
|
4.2.2.2. |
PRUEM_header dir Тип данни, съдържащи се в съобщението — възможни стойности:
|
|
4.2.2.3. |
PRUEM header info Структура, описваща държавата-членка и датата/часа на съобщението. Съдържа следните полета:
|
4.2.3.
|
4.2.3.1. |
Данни по линия на Прюм (PRUEM_datas) Тази структура описва частта за данни за профила на XML-файла. Съдържа следните полета:
|
|
4.2.3.2. |
Тип искане по линия на Прюм (PRUEM_request_type) Тип данни, съдържащи се в съобщението — възможни стойности:
|
|
4.2.3.3. |
Тип качество на съвпадения по линия на Прюм (PRUEM_hitquality_type)
|
|
4.2.3.4. |
Тип данни по линия на Прюм (PRUEM_data_type) Тип данни, съдържащи се в съобщението — възможни стойности:
|
|
4.2.3.5. |
PRUEM_data_result Тип данни, съдържащи се в съобщението — възможни стойности:
|
|
4.2.3.6. |
IPSG_DNA_profile Структура, описваща ДНК профил. Съдържа следните полета:
|
|
4.2.3.7. |
IPSG_DNA_ISSOL Структура, съдържаща локусите на ISSOL (стандартния набор на Интерпол от локуси). Съдържа следните полета:
|
|
4.2.3.8. |
IPSG_DNA_additional_loci Структура, съдържаща другите локуси. Съдържа следните полета:
|
|
4.2.3.9. |
IPSG_DNA_locus Структура, описваща локус. Съдържа следните полета:
|
5. Архитектура на приложението, сигурността и комуникациите
5.1. Обзорен преглед
При внедряването на приложенията за обмен на ДНК данни в рамките на Решение 2008/615/ПВР се използва обща комуникационна мрежа, която е логически затворена между държавите-членки. С цел експлоатиране по по-ефективен начин на тази обща комуникационна инфраструктура за изпращане на искания и получаване на отговори се възприема асинхронен механизъм за предаване на исканията за ДНК данни и дактилоскопични данни в капсулирани SMTP-електронни съобщения. С цел да се удовлетворят изискванията за сигурност, като разширение на SMTP-функционалността ще се използва механизъм sMIME, за да се установи действително затворен сигурен „тунел“ за работата в мрежата.
Оперативната TESTA (трансевропейски телематични услуги между администрациите) се използва за комуникационна мрежа за обмена на данни между държавите-членки. TESTA се управлява от Европейската комисия. С оглед на факта, че националните ДНК бази данни и действащите национални точки за достъп до TESTA могат да бъдат разположени на различни места в държавите-членки, достъпът до TESTA може да се осигури, като:
|
1. |
се използват съществуващите национални точки за достъп или се създаде нова национална точка за достъп до TESTA; или |
|
2. |
се създаде защитена местна връзка от обекта, където е разположена ДНК базата данни, управлявана от компетентната национална служба, до съществуващата национална точка за достъп до TESTA. |
Протоколите и стандартите, внедрени в приложенията, използвани за изпълнението на Решение 2008/615/ПВР, съответстват на отворените стандарти и отговарят на изискванията, наложени от органите, определящи националната политиката по отношение на сигурността в държавите-членки.
5.2. Архитектура на горното ниво
В обхвата на Решение 2008/615/ПВР всяка държава-членка ще прави налични нейните ДНК данни за целите на обмена на такива данни и/или търсения в тях от други държави-членки в съответствие със стандартизирания общ формат на данните. Архитектурата е снована на комуникационен модел, при който се осъществява връзка „от всеки до всеки“. Не съществува централен компютърен сървър, нито централизирана база данни за съхранение на ДНК профили.
Фигура 1: Топология на обмена на ДНК данни

Освен спазването на националните правни ограничения, касаещи съответните обекти в държавите-членки, всяка държава-членка може да реши какъв вид хардуер и софтуер следва да се внедри за конфигуриране в съответния обект, така че да са спазени изискванията на Решение 2008/615/ПВР.
5.3. Стандарти за сигурност и защита на данните
Три са нивата на сигурност, които са взети под внимание и са въведени.
5.3.1.
Предоставяните от държавите-членки данни за ДНК профили трябва да се изготвят в съответствие с общите стандарти за защита на данните, така че отправилата искането държава-членка да получи отговор, в който основно се посочва наличие на попадение или липса на попадение (HIT/NO-HIT) заедно с идентификационен номер в случай на попадение, но в него не се съдържа никаква лична информация. По-нататъшното разследване след уведомяване за наличие на попадение се води на двустранно равнище съгласно съществуващите национални правни и организационни разпоредби, уреждащи съответните обекти в държавите-членки.
5.3.2.
Съобщенията, съдържащи информация за ДНК профили (искания и отговори), се криптират посредством най-модерен механизъм в съответствие с отворените стандарти, като sMIME, преди да се изпратят в съответните обекти в държавите-членки.
5.3.3.
Всички криптирани съобщения, съдържащи информация за ДНК профили, се изпращат в обектите на другите държави-членки посредством виртуална частна тунелираща система администрирана от надежден доставчик на мрежови услуги на национално равнище и връзките за сигурност към тази тунелираща система са под национално управление. Виртуалната частна тунелираща система няма никакъв точка на контакт с откритата интернет мрежа.
5.4. Протоколи и стандарти, които да се използват за механизма за криптиране sMIME и свързани пакети
Отвореният стандарт sMIME, като разширение на действащия de facto стандарт за електронна поща SMTP, ще се внедри за криптиране на съобщения, съдържащи информация за ДНК профили. Протоколът sMIME (V3) позволява електронно подписана разписка, етикети за сигурност и защитени списъци с електронни адреси (mailing lists), като е базиран върху „пласта“ на Cryptographic Message Syntax (CMS), IETF спецификация за защитени чрез криптиране съобщения. Той може да се използва за електронно подписване, резюмиране, автентификация или криптиране на всякакви форма цифрови данни.
Сертификатът, на базата на който се прилага механизмът sMIME, трябва да съответства на стандарта X.509. С цел да се осигурят стандарти и процедури, които са общи с тези за други приложения, използвани по линия на Прюм, правилата за обработване за операциите по криптиране на базата на sMIME или за прилагане в различни видове среда на базата на готови търговски продукти (Commercial Product of the Shelves — COTS), са следните:
|
— |
последователността на операциите е: първо криптиране и след това подписване, |
|
— |
за симетрично и асиметрично криптиране се прилагат съответно алгоритмите за криптиране AES (Advanced Encryption Standard) с 256-битов ключ и RSA с 1 024-битов ключ, |
|
— |
прилага се hash-алгоритъм SHA-1. |
Функционалността s/MIME е вградена в повечето съвременни софтуерни пакети за електронна поща, в т.ч. Outlook, Mozilla Mail и Netscape Communicator 4.x, като позволява оперативна съвместимост между повечето основни софтуерни пакети за електронна поща.
Поради лесното интегриране на sMIME в националната ИТ инфраструктура във всички държави-членки, този механизъм е избран като подходящ с цел осигуряване на сигурността на ниво комуникации. С цел по-ефикасен „тест на концепцията“ („Proof of Concept“) и намаляване на разходите обаче е избран стандартът JavaMail API, с който да се извърши прототипирането на обмена на ДНК данни. JavaMail API предоставя елементарно криптиране и декриптиране на електронни съобщения посредством s/MIME и/или OpenPGP. Целта е да се осигури прост и лесен за употреба програмно-приложен интерфейс (API) за клиентите на електронна поща, които желаят да изпращат и получават криптирани електронни съобщения в един от двата най-популярни формата за криптиране на електронни съобщения. Следователно, за да са изпълнени изискванията на Решение 2008/615/ПВР, ще е достатъчно високотехнологично внедряване на базата на JavaMail API, като например продуктът на Bouncy Castle JCE (Java Cryptographic Extension), който ще се използва за въвеждането на sMIME за прототипирането на обмена на ДНК данни между държавите-членки.
5.5. Архитектура на приложението
Всяка държава-членка ще предостави на другите държави-членки набор от стандартизирани данни за ДНК профили, които съответстват на използвания в момента общ документ за контрол на интерфейса (ICD). Това може да стане или чрез предоставяне на логически поглед върху индивидуалната национална база данни, или чрез установяване на физически експортирана база данни (индексирана база данни).
Четирите основни компонента: сървърът за електронна поща/sMIME, сървърът за приложението, зоната на структурирани данни (Data Structure Area) за извличане/подаване на данни и регистрация на входящите/изходящите съобщения, както и търсачката за стравняване, внедряват цялостната логика на приложението по начин, който не зависи от конкретните продукти.
За да се осигури на всички държави-членки възможност да интегрират лесно тези компоненти в съответните си национални обекти, конкретно определената обща функционалност е внедрена посредством компоненти с отворен код, които могат да се избират от всяка държава-членка в зависимост от нейната национална политика и уредба в областта на ИТ. Поради независимите характеристики на внедряваната система за получаване на достъп до индексирани бази данни с ДНК профили, обхванати от Решение 2008/615/ПВР, всяка държава-членка може свободно да избира собствената си хардуерна и софтуерна платформа, включително системите за бази данни и операционните системи.
Прототипът за обмена на ДНК данни е разработен и успешно изпитан в съществуващата обща мрежа. Вариант 1.0 е внедрен в работната среда и се използва за ежедневната дейност. Държавите-членки могат да използват разработения съвместно продукт, но също така могат да разработят свои продукти. Компонентите на общия продукт ще се поддържат, приспособяват и доразвиват в съответствие с изменящите се изисквания за функционалност по отношение на ИТ, криминалистиката и/или полицейската работа.
Фигура 2: Обща топология на приложението

5.6. Протоколи и стандарти, които да се използват за архитектурата на приложението
5.6.1.
Обменът на ДНК данни ще използва изцяло XML-схемата като ги прикачва към SMTP-електронни съобщения. Езикът XML (eXtensible Markup Language) се препоръчва от консорциума World Wide Web (W3C) като общофункционален метаезик за създаване на специализирани метаезици, способни да описват множество различни видове данни. Описанието на ДНК профила, който е подходящ за обмен между всички държави-членки, е изготвено посредством XML и XML-схема в ICD.
5.6.2.
ODBC (Open DataBase Connectivity) предоставя стандартен софтуерен API метод за достъп до системи за управление на бази данни, който е независим от езиците за програмиране, от системите за базите данни и операционните системи. ODBC обаче си има своите недостатъци. Администрирането на голям брой клиентски машини може да е свързано с разнообразие на драйверите и DLL файловете. Това усложнение може да повиши разходите за администриране на системата.
5.6.3.
JDBC (Java DataBase Connectivity) представлява API за програмния език Java, който определя какъв достъп има клиентът до базата данни. За разлика от работата с ODBC, при JDBC не се изисква да се използва даден набор от местни DLL файлове на десктопа.
Работната логика на обработката на искания и отговори за ДНК профили в съответния обект на всяка държава-членка е описана в дадената по-долу диаграма. Потоците на исканията и на отговорите взаимодействат с неутрална зона за данни, която обхваща различни масиви с еднакво структурирани данни.
Фигура 3: Обща картина на работните потоци в приложенията в съответния обект на всяка държава-членка

5.7. Комуникационна среда
5.7.1.
Приложението за обмен на ДНК данни ще използва електронната поща, асинхронен механизъм, за изпращане на искания и получаване на отговори между държавите-членки. Тъй като всички държави-членки разполагат с поне една точка за достъп до мрежата TESTA, обменът на ДНК данни ще се осъществява по мрежата TESTA. TESTA осигурява редица услуги с добавена стойност посредством своята система за предаване на електронна поща. Освен хостването на специално предназначени за TESTA електронни пощенски кутии, инфраструктурата може да работи със списъци за разпределяне на съобщения и политики за маршрутизиране. Това позволява TESTA да се използва като разпределителен център за съобщенията, адресирани до администрациите, свързани с домейните в рамките на ЕС. Възможно е също така да се включат и механизми за проверка за вируси.
Системата на TESTA за предаване на електронна поща е изградена на базата на хардуерна платформа с висока степен на наличност, която е разположена в централното приложение на TESTA и е защитена с firewall. Чрез DNS (Domain Name Services) на TESTA ще се определят ресурсните локатори за IP-адресите и ще се скрива информацията по адресирането от потребителя и от приложението.
5.7.2.
В рамките на TESTA е приложена концепцията за VPN (Virtual Private Network). Технологията за Tag Switching, която е използвана за изграждане на тази VPN ще бъде доразвита, така че да поддържа стандарта MPLS (Multi-Protocol Label Switching), разработен от IETF (Internet Engineering Task Force).
|
|
MPLS представлява стандартна технология на IETF, която ускорява мрежовия трафик, като избягва пакетния анализ посредством междинни рутери („hops“). Това се прави на базата на т.нар. „етикети“, които се прикрепват към пакета от edge-рутерите в backbone въз основа на информацията, съхранена в информационната база за препращане (FIB). Етикети се използват и за внедряване на виртуалните частни мрежи (VPN). |
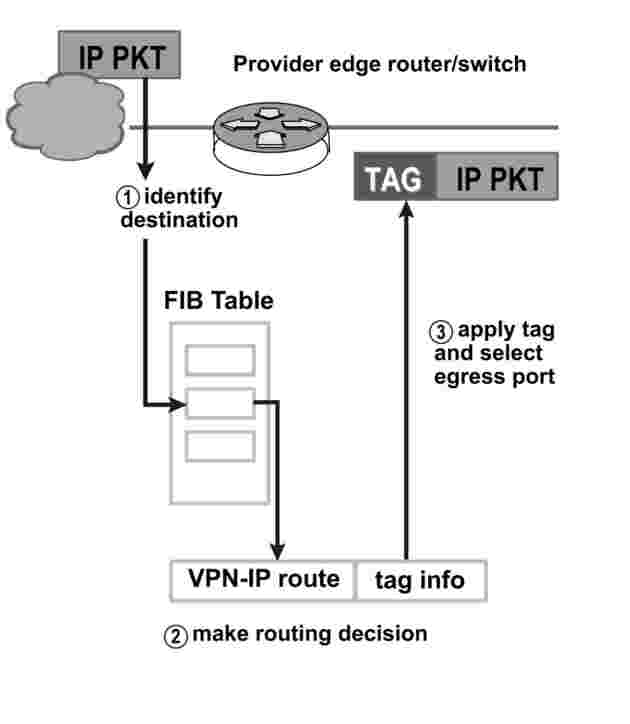
В MPLS се съчетават ползите от маршрутизирането в пласт 3 с предимствата на суичинга в пласт 2. Тъй като на IP-адресите не се прави оценка при преминаването им през т.нар. „backbone“, MPLS не налага никакви ограничения на IP-адресирането.
Освен това електронните съобщения, предавани по TESTA, ще бъдат защитени с механизъм за криптиране на базата на sMIME. Никой не може да декриптира съобщенията по мрежата, ако не знае ключа и не разполага със съответния сертификат.
5.7.3.
|
5.7.3.1. |
SMTP SMTP (Simple Mail Transfer Protocol) е действащият стандарт за пренос на електронна поща по Интернет. SMTP е относително прост текстови протокол, при който се определя един или повече получатели на съобщението, след което то се изпраща. SMTP използва TCP порт 25 по спецификациите на IETF. За да се определи SMTP сървърът за дадено име на домейн, се използва записване по MX (Mail eXchange) DNS (Domain Name Systems). Тъй като този протокол отначало беше изцяло и само текстови на базата на ASCII, той не работеше добре с бинарни файлове. Стандарти като MIME бяха разработени, за да се кодират бинарни файлове за изпращане чрез SMTP. Днес повечето SMTP сървъри поддържат 8BITMIME и sMIME разширения, позволявайки изпращането на бинарни файлове да става почти толкова лесно, колкото и обикновен текст. Правилата за работа при операции с sMIME са описани в раздела „sMIME“ (вж. точка 5.4). SMTP представлява push-протокол, който не позволява изтегляне на съобщения от физически отдалечен сървър по заявка. За да изтегли съобщение, клиентът на електронна поща трябва да използва POP3 или IMAP. За осъществяването на обмен на ДНК данни е решено да се използва POP3 протокол. |
|
5.7.3.2. |
POP Местните клиенти за електронна поща използват POP3 (Post Office Protocol version 3), протокол за интернет стандарт за пласта на приложението (application-layer Internet standard protocol), за да извлекат електронното съобщение от физически отдалечен сървър по TCP/IP връзка. Като използва профила SMTP Submit на SMTP протокола, клиентът на електронна поща изпраща съобщения по интернет или по корпоративна мрежа. MIME служи за стандарт за прикрепени файлове и текст, който не е ASCII, в електронното съобщение. Въпреки че нито POP3, нито SMTP изискват електронното съобщение да е в MIME-формат, предаваните по интернет електронни съобщения са основно в MIME-формат, така че POP-клиентите трябва също така да разбират и да използват MIME. Поради това в цялата комуникационна среда на Решение 2008/615/ПВР ще бъдат включени компонентите на POP. |
5.7.4.
Операционна среда
Понастоящем Европейският орган за регистрация на IP-адреси (RIPE) е определил за TESTA един специализиран блок от подмрежа клас С. По-нататък, ако е необходимо, за TESTA могат да бъдат определени и други блокове за адреси. Определянето на IP-адреси за държавите-членки се основава на географска схема в Европа. Обменът на данни между държавите-членки в рамките на Решение 2008/615/ПВР се осъществява по логически затворената европейска IP-мрежа.
Изпитателна среда
С цел да се осигури среда за безпрепятствено осъществяване на ежедневната работа между всички свързани държави-членки, е необходимо да се установи изпитателна среда в защитената мрежа за новите държави-членки, които се готвят да се присъединят към тези операции. Изготвен е документ с параметрите, включително IP-адреси, мрежови настройки, домейни за електронна поща, както и потребителски акаунти за приложенията, които следва да се конкретизират и установят в съответните обекти на държавите-членки. Освен това за целите на изпитванията е конструиран масив от псевдо ДНК профили.
5.7.5.
Създадена е защитена мрежа за електронна поща, за което е използван домейнът eu-admin.net. Този домейн с асоциираните му адреси няма да бъде достъпен от места извън домейна на TESTA за ЕС, тъй като имената са известни само на централния DNS-сървър на TESTA, който е отделен от интернет със специална защита.
Превръщането на тези адреси на сайтове (host names) в TESTA в съответните им IP-адреси се осъществява от DNS-услугите на TESTA. В този централен DNS-сървър на TESTA се добавя вписване за пощата, като всички електронни съобщения, изпратени до местните домейни на TESTA, се предават на центъра за предаване на поща на TESTA. Този център за предаване на поща на TESTA след това ги препраща към конкретния сървър за електронна поща на местния домейн, като се използват адресите за електронна поща на местния домейн. Чрез предаването на електронната поща по този начин, критична информация, която се съдържа в електронните съобщения, ще преминава само по европейската защитената мрежова инфраструктура, а не по незащитен интернет.
Необходимо е в обектите на всички държави-членки да се установят поддомейни ( получерен курсив ), следвайки следния синтаксис:
„application-type.pruem.Member State-code.eu-admin.net“, където:
„Member State-code“ приема стойността на един от двубуквените кодове на държавите-членки (напр. AT, BE и т.н.).
„ application-type “ приема една от стойностите: DNA или FP.
Като се приложи горепосоченият синтаксис, поддомейните на държавите-членки са посочени в таблицата по-долу:
|
MS |
Sub Domains |
Comments |
|
BE |
dna.pruem.be.eu-admin.net |
Setting up a secure local link to the existing TESTA II access point |
|
fp.pruem.be.eu-admin.net |
|
|
|
BG |
dna.pruem.bg.eu-admin.net |
|
|
fp.pruem.bg.eu-admin.net |
|
|
|
CZ |
dna.pruem.cz.eu-admin.net |
|
|
fp.pruem.cz.eu-admin.net |
|
|
|
DK |
dna.pruem.dk.eu-admin.net |
|
|
fp.pruem.dk.eu-admin.net |
|
|
|
DE |
dna.pruem.de.eu-admin.net |
Using the existing TESTA II national access points |
|
fp.pruem.de.eu-admin.net |
|
|
|
EE |
dna.pruem.ee.eu-admin.net |
|
|
fp.pruem.ee.eu-admin.net |
|
|
|
IE |
dna.pruem.ie.eu-admin.net |
|
|
fp.pruem.ie.eu-admin.net |
|
|
|
EL |
dna.pruem.el.eu-admin.net |
|
|
fp.pruem.el.eu-admin.net |
|
|
|
ES |
dna.pruem.es.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.es.eu-admin.net |
|
|
|
FR |
dna.pruem.fr.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.fr.eu-admin.net |
|
|
|
IT |
dna.pruem.it.eu-admin.net |
|
|
fp.pruem.it.eu-admin.net |
|
|
|
CY |
dna.pruem.cy.eu-admin.net |
|
|
fp.pruem.cy.eu-admin.net |
|
|
|
LV |
dna.pruem.lv.eu-admin.net |
|
|
fp.pruem.lv.eu-admin.net |
|
|
|
LT |
dna.pruem.lt.eu-admin.net |
|
|
fp.pruem.lt.eu-admin.net |
|
|
|
LU |
dna.pruem.lu.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.lu.eu-admin.net |
|
|
|
HU |
dna.pruem.hu.eu-admin.net |
|
|
fp.pruem.hu.eu-admin.net |
|
|
|
MT |
dna.pruem.mt.eu-admin.net |
|
|
fp.pruem.mt.eu-admin.net |
|
|
|
NL |
dna.pruem.nl.eu-admin.net |
Intending to establish a new TESTA II access point at the NFI |
|
fp.pruem.nl.eu-admin.net |
|
|
|
AT |
dna.pruem.at.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.at.eu-admin.net |
|
|
|
PL |
dna.pruem.pl.eu-admin.net |
|
|
fp.pruem.pl.eu-admin.net |
|
|
|
PT |
dna.pruem.pt.eu-admin.net |
...... |
|
fp.pruem.pt.eu-admin.net |
...... |
|
|
RO |
dna.pruem.ro.eu-admin.net |
|
|
fp.pruem.ro.eu-admin.net |
|
|
|
SI |
dna.pruem.si.eu-admin.net |
...... |
|
fp.pruem.si.eu-admin.net |
....... |
|
|
SK |
dna.pruem.sk.eu-admin.net |
|
|
fp.pruem.sk.eu-admin.net |
|
|
|
FI |
dna.pruem.fi.eu-admin.net |
[To be inserted] |
|
fp.pruem.fi.eu-admin.net |
|
|
|
SE |
dna.pruem.se.eu-admin.net |
|
|
fp.pruem.se.eu-admin.net |
|
|
|
UK |
dna.pruem.uk.eu-admin.net |
|
|
fp.pruem.uk.eu-admin.net |
|
ГЛАВА 2: Обмен на дактилоскопични данни (документ за контрол на интерфейса)
Целта на следния документ за контрол на интерфейса е да определи изискванията за обмена на дактилоскопична информация между системите на държавите-членки за автоматизирана идентификация на пръстови отпечатъци (AFIS). Документът се основава на прилагания от Интерпол ANSI/NIST-ITL 1-2000 (INT-I, Version 4.22b).
Настоящата версия обхваща всички основни дефиниции за логически записи тип-1, тип-2, тип-4, тип-9, тип-13 и тип-15, които са необходими за обработката на дактилоскопични данни на базата на изображения и признаци (minutiае).
1. Обзор на съдържанието на файловете
Дактилоскопичният файл се състои от няколко логически записа. В оригиналния стандарт ANSI/NIST-ITL 1-2000 са определени шестнадесет типа записи. За разделяне на записите и на техните полета и подполета се използват подходящи разделителни ASCII символи.
За обмен на информация между службата по произход и службата по местоназначението се използват само 6 типа записи:
|
Тип-1 |
→ |
информация за транзакция |
|
Тип-2 |
→ |
буквено-цифрови данни за лица/случай |
|
Тип-4 |
→ |
дактилоскопични изображения с висока резолюция в сивата скала |
|
Тип-9 |
→ |
запис на признаци (minutiae) |
|
Тип-13 |
→ |
запис на изображение на следи с променлива резолюция |
|
Тип-15 |
→ |
запис на изображение на отпечатък от длан с променлива резолюция |
1.1. Тип-1 — заглавна част на файла
Този запис съдържа маршрутизираща информация и информация, описваща структурата на останалата част от файла. В този тип записи също така се описват типовете транзакции, които попадат в следните по-широки категории:
1.2. Тип-2 — описателен текст
Този запис съдържа текстова информация, която е от интерес за изпращащата и получаващата служба.
1.3. Тип-4 — изображение с висока резолюция в сивата скала
Този запис се използва за обмен на дактилоскопични изображения с висока резолюция в сивата скала (осем бита), снети при резолюция 500 пиксела/инч. Дактилоскопичните изображения се компресират, като се използва WSQ-алгоритъм при съотношение не повече от 15:1. Не трябва да се използват други алгоритми за компресия или некомпресирани изображения.
1.4. Тип-9 — запис на признаци (minutiае)
Записите тип-9 се използват за обмен на характеристики на папиларните линии и данни за признаците. Тяхната цел е от една страна да се избегне ненужното дублиране на процесите за кодиране в AFIS, от друга — да се позволи изпращането на AFIS кодове, които съдържат по-малко информация отколкото съответните изображения.
1.5. Type-13 — запис на изображение на следи с променлива резолюция
Този запис се използва за обмен на изображения на следи от пръстови отпечатъци и на следи от длан с променлива резолюция, придружавани от буквено-цифрова текстурна информация. Резолюцията на сканиране на изображенията е 500 пиксела/инч с 256 нива на сивото. Ако качеството на изображението на следа е задоволително, то се компресира по WSQ алгоритъм. Ако е необходимо, на основата на двустранно споразумение, може резолюцията на изображенията да се увеличи на повече от 500 пиксела/инч и повече от 256 нива на сивото. В този случай е силно препоръчително да се използва JPEG 2000 (вж. допълнение 7).
1.6. Запис на изображение на отпечатък от длан с променлива резолюция
Записи тип-15 на изображения с маркировка на полетата се използват за обмен на изображения на отпечатък от длан с променлива резолюция, придружавани от буквено-цифрова текстурна информация. Резолюцията на сканиране на изображенията е 500 пиксела/инч с 256 нива на сивото. За да се намали максимално обемът на данните, всички изображения на отпечатък от длан се компресират като се използва WSQ алгоритъм. Ако е необходимо, на основата на двустранно споразумение, резолюцията на изображенията може да се увеличи на повече от 500 пиксела/инч и повече от 256 нива на сивото. В този случай е препоръчително да се използва JPEG 2000 (вж. допълнение 7).
2. Формат на записите
Файлът за транзакция се състои от един или повече логически записа. За всеки логически запис, който се съдържа във файла, има по няколко информационни полета, подходящи за типа запис. Всяко информационно поле може да съдържа една или повече на брой информационни единици с единична стойност. Тези единици взети заедно се използват за предаване на различни аспекти на данните, които се съдържат в съответното поле. Информационното поле може да се състои също така от една или повече информационни единици, които са групирани и повторени неколкократно в рамките на полето. Групираните по този начин информационни единици са познати като подполе. Следователно, информационното поле може да се състои от едно или повече подполета от информационни единици.
2.1. Информационни разделители
В логическите записи с тагови полета, се прилагат механизми за отграничаване на информацията, посредством използването на четири ASCII разделителя. По този начин могат да се отграничават отделни единици в рамките на полето или подполето, полетата в рамките на логическия запис или многократно появяващи се подполета. Разделителите на информацията са дефинирани в стандарта ANSI X3.4. Тези символи се използват за логическо разделяне и категоризиране на информацията. Представени йерархично, символът за разделяне на файлове (FS) има най-широк обхват, следван от символа за разделяне на групи (GS), символа за разделяне на записи (RS) и накрая — символа за разделяне на единици (US). В таблица 1 са изброени тези ASCII разделители и е дадено описание на употребата им в настоящия стандарт.
Във функционално отношение информационните разделители следва да се разглеждат като указание за типа на данните, които следват. Със символ US се разделят отделни информационни единици в рамките на полето или подполето. Това е сигнал, че следващата информационна единица е част от данните за това поле или подполе. Множество подполета в рамките на същото поле, отделено със символ RS, сигнализира за започването на следваща група от повтаряща(и) се информационна(и) единица(и). Разделителният символ GS, използван между информационните полета, сигнализира за началото на ново поле, предшестващо идентификационния номер на полето, което се появява. По същия начин, началото на нов логически запис се сигнализира от появата на символа FS.
Четирите символа имат смисъл само когато са използвани като разделители на информационни единици в полетата на ASCII текстови записи. Когато тези символи се срещат в бинарни записи на изображения и бинарни полета не им се придава конкретен смисъл — те представляват част от обменяните данни.
Обикновено не следва да има празни полета или информационни единици, поради което между две единици данни следва да появява само един разделител. Изключение от това правило възниква в тези случаи, когато данните в полетата или информационните единици на транзакцията не са налични, липсват или не са задължителни и обработката на транзакцията не зависи от присъствието на точно тези данни. В тези случаи се появяват няколко и адаптиращи разделителни символа заедно, вместо да се изисква вмъкване на заместители на данни между разделителните символи.
За дефиниране на поле, което се състои от три информационни единици, се прилага следното: ако липсва информацията за втората информационна единица, тогава се появяват два съседни разделителя US между първата и третата информационна единица; ако липсват и втората и третата информационна единица, тогава се използват три разделителни символа — два символа US в допълнение към символа за край на полето или към разделителния символ на подполето. По принцип ако не са налични една или повече задължителни или незадължителни информационни единици в рамките на едно поле или подполе, следва да се постави съответният брой разделителни символи.
Възможно е да се получат съседни комбинации от два или повече от четирите вида разделителни символи. Когато отсъстват или не са налични данни за информационните единици, подполета или полета, трябва да има един разделителен символ по-малко, отколкото са задължителните информационни единици, подполета или полета.
Таблица 1: Използвани разделители
|
Code |
Type |
Description |
Hexadecimal Value |
Decimal Value |
|
US |
Unit Separator |
Separates information items |
1F |
31 |
|
RS |
Record Separator |
Separates subfields |
1E |
30 |
|
GS |
Group Separator |
Separates fields |
1D |
29 |
|
FS |
File Separator |
Separates logical records |
1C |
28 |
2.2. Изглед на записите
При логическите записи с тагови полета всяко използвано информационно поле се номерира в съответствие с настоящия стандарт. Форматът за всяко поле се състои от номера на типа логически запис, следван на разстояние от точка „.“, номер на полето, следван от двоеточие „:“, след което подходяща информация за това поле. Таговото поле може да се номерира с всяка цифра от едно до девет, като номерът се повява между точката „.“ и двоеточието „:“. Интерпретира се като номер на поле с непълно изписване. Това означава, че номерът на поле „2123:“ е равностоен на номера на поле „2.000000123:“ и се интерпретира по същия начин.
С цел илюстрация в настоящия документ се използват трицифрени номера за номериране на полетата, които се съдържат във всеки от описаните тук логическите записи с тагови полета. Номерата на полетата са в следния формат: „TT.xxx:“ където „ТТ“ представлява едносимволен или двусимволен тип запис, следван от точка. Следващите три символа съставят съответния номер на полето, следван от двоеточие След двоеточието се намира описателната ASCII информация или данните на изображението.
Логическите записи тип-1 и тип-2 съдържат само полета с ASCII текст. Цялата дължина на записа (включително номерата на полета, двоеточията и разделителните символи) се записва като първо ASCII поле във всеки от посочените типове записи. Контролният ASCII символ за разделяне на файлове FS (който означава край на логическия запис или транзакция) се поставя след последния байт ASCII информация и се включва в дължината на записа.
За разлика от концепцията за таговите полета, запис тип-4 съдържа само бинарни данни, записани като поредица от бинарни полета с фиксирана дължина. Цялата дължина на записа се отразява в първото четирибайтово бинарно поле на съответния запис. За този бинарен запис не се отразява нито номер на записа със съответната точка в края, нито идентификационен номер на полето със съответното двоеточие. Освен това, тъй като всички дължини на полета на този тип запис са или фиксирани, или конкретно определени, никой от четирите разделителни символа (US, RS, GS или FS) не се интерпретира по друг начин освен като бинарни данни. За бинарния запис символът FS не се използва за разделяне на записите или като символ, завършващ транзакцията.
3. Логически запис тип-1: заглавна част на файла
Този запис описва структурата на файла, типа на файла и друга важна информация. Наборът от символи, използвани за полета на тип-1 се състои единствено от 7-битов ANSI код за информационен обмен.
3.1. Полета на логически запис тип-1:
3.1.1.
В това поле се съдържа общия брой байтове в целия логически запис тип-1. Полето започва с „1.001:“, следвано от дължината на целия запис, в т.ч. всички символи на всички полета заедно с информационните разделители.
3.1.2.
За да е сигурно, че потребителите знаят коя е използваната версия на стандарта ANSI/NIST, в това четирибайтово поле се посочва номерът на версията на стандарта, който е приложен от софтуера или системата, генерирали този файл. Първите два байта посочват номера на основната версия, а вторите два — номера на подверсията. Например, оригиналният стандарт от 1986 г. се счита за първа версия и се означава с „0100“, докато сегашният стандарт ANSI/NIST-ITL 1-2000 е „0300“.
3.1.3.
Това поле изброява всеки от записите във файла според типа и реда, в който записите се появяват в логическия файл. Състои се от едно или повече подполета, всяко от които на свой ред съдържа две информационни единици, описващи един от логическите записи в текущия файл. Подполетата се вписват по реда на записването и изпращането на записите.
Първата информационна единица в първото подполе е „1“, с което се отбелязва, че въпросния запис е тип-1. Той се следва от втора информационна единица, която съдържа числото на броя на останалите записи, които се съдържат във файла. Това число е равно на броя на останалите подполета на поле 1.003.
Всяко от останалите подполета се асоциира с един от записите във файла, а редът на изброяване на подполетата съответства на последователността на записите. Всяко подполе съдържа две информационни единици. Първата показва какъв тип е записът. Втората е символът за означаване на изображението (IDC) в записа. За разделяне на двете информационни единици се използва символът US.
3.1.4.
Това поле съдържа трибуквено мнемонично съчетание, с което се означава типът транзакция. Тези кодове могат да се различават кодовете, които се използват в други случаи на прилагане на стандарта ANSI/NIST.
CPS (Criminal Print-to-Print Search): търсене на отпечатъци на правонарушител. Тази транзакция представлява искане за търсене на запис, свързан с престъпление, чрез сравняване на отпечатъци в база данни. Отпечатъците на лицето трябва да се включат във файла като WSQ-компресирани изображения.
Ако не се установи попадение (No-HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record |
|
— |
1 Type-2 Record |
Ако се установи попадение (HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record |
|
— |
1 Type-2 Record |
|
— |
1-14 Type-4 Record |
В таблица A.6.1 (допълнение 6) е представен накратко TOT CPS.
PMS (Print-to-Latent Search): търсене чрез сравняване на отпечатъци със следи. Тази транзакция се използва, когато в база данни с неидентифицирани следи се извършва търсене за определен набор отпечатъци. В отговора се съдържа решението за наличие или отсъствие на попадение (Hit/No-Hit) при търсенето в AFIS по местоназначение. Ако има повече неидентифицирани следи, се отговаря с няколко SRE транзакции — по една отделна транзакция за всяка следа. Отпечатъците на лицето трябва да се включат във файла като WSQ-компресирани изображения.
Ако не се установи попадение (No-HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record |
|
— |
1 Type-2 Record. |
Ако се установи попадение (HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record |
|
— |
1 Type-2 Record |
|
— |
1 Type-13 Record. |
В таблица A.6.1 (допълнение 6) е представен накратко TOT PMS.
MPS (Print-to-Latent Search): търсене чрез сравняване на следи с отпечатъци. Тази транзакция се използва, когато трябва да се търсят съответствия на следи в база данни с отпечатъци. Във файла трябва да се включи информацията за признаците (minutiае) на следите и изображението (WSQ-компресия).
Ако не се установи попадение (No-HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record, |
|
— |
1 Type-2 Record. |
Ако се установи попадение (HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record, |
|
— |
1 Type-2 Record, |
|
— |
1 Type-4 or Type-15 Record. |
В таблица A.6.4 (допълнение 6) е представен накратко TOT MPS.
MMS (Latent-to-Latent Search): търсене чрез сравняване на следи със следи. При тази транзакция файлът съдържа следа, за която се прави търсене в база данни с неидентифицирани следи, за да се установи връзка между различни местопрестъпления. Във файла трябва да се включи информацията за признаците (minutiае) на следите и изображението (WSQ-компресия).
Ако не се установи попадение (No-HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record, |
|
— |
1 Type-2 Record. |
Ако се установи попадение (HIT), се изпраща следният логически запис:
|
— |
1 Type-1 Record, |
|
— |
1 Type-2 Record, |
|
— |
1 Type-13 Record. |
В таблица A.6.4 (допълнение 6) е представен накратко TOT MMS.
SRE: Тази транзакция се изпраща от службата по местоназначение в отговор на заявка с дактилоскопични данни. В отговора се съдържа решението за наличие или отсъствие на попадение (Hit/No-Hit) при търсенето в AFIS по местоназначение. Ако са налице няколко кандидати, се отговаря с няколко SRE транзакции — отделна транзакция за всеки кандидат.
В таблица A.6.2 (допълнение 6) е представен накратко TOT SRE.
ERR: тази транзакция се изпраща от AFIS по местоназначение, за да се посочи, че има грешка. В нея се включва поле за съобщение (ERM), в което се посочва установената грешка. Изпраща се следният логически запис:
|
— |
1 Type-1 Record, |
|
— |
1 Type-2 Record. |
В таблица A.6.3 (допълнение 6) е представен накратко TOT ERR.
Таблица 2: Допустими кодове в транзакциите
|
Transaction Type |
Logical Record Type |
|||||
|
1 |
2 |
4 |
9 |
13 |
15 |
|
|
CPS |
M |
M |
M |
— |
— |
— |
|
SRE |
M |
M |
C |
— (C in case of latent hits) |
C |
C |
|
MPS |
M |
M |
— |
M (1*) |
M |
— |
|
MMS |
M |
M |
— |
M (1*) |
M |
— |
|
PMS |
M |
M |
M* |
— |
— |
M* |
|
ERR |
M |
M |
— |
— |
— |
— |
Легенда:
|
M |
= |
задължително |
|
M* |
= |
може да се включи само един от двата типа записи |
|
O |
= |
незадължително |
|
C |
= |
в зависимост от това, дали има налични данни |
|
— |
= |
недопустимо |
|
1* |
= |
в зависимост от това какви са „наследените“ системи |
3.1.5.
В това поле се посочва датата, на която е започнала транзакцията, като се използва стандартният формат на ISO: YYYYMMDD
където YYYY е годината, MM е месецът, а DD е денят от месеца. Единичните цифри се предшестват от нула. Например „19931004“ означава 4 октомври 1993 г.
3.1.6.
Това незадължително поле описва приоритета на искането по скала от 1 до 9, като „1“ е най-високият приоритет, а „9“ е най-ниският. Транзакциите с приоритет „1“ се обработват незабавно.
3.1.7.
В това поле се посочва службата по местоназначение на транзакцията.
Състои се от две информационни единици в следния формат: CC/служба.
Първата информационна единица съдържа кода на държавата, определен по ISO 3166, с дължина два буквено-цифрови символа. Втората единица, службата, представлява свободен текст за идентификация на службата — не повече от 32 буквено-цифрови символа.
3.1.8.
В това поле се посочва службата на произход и се използва същият формат като този за DAI (поле 1.007).
3.1.9.
Това е контролен номер за справочни цели. Той следва да се генерира от компютъра и е в следния формат: YYSSSSSSSSA
където YY е годината на транзакцията, SSSSSSSS е 8-цифров сериен номер, а A е контролен символ, генериран по процедурата, описана в допълнение 2.
Където няма TCN, полето YYSSSSSSSS се запълва с нули и се генерира контролен символ по начина, описан по-горе.
3.1.10.
Когато има изпратено искане, на което настоящото се явява отговор, в това незадължително поле се дава контролният номер на транзакцията, с която е изпратено искането. Следователно, то има същия формат като TCN (поле 1.009).
3.1.11.
В това поле се посочва нормалната резолюция на сканиране на системата, с която работи службата-подател на транзакцията. Резолюцията се посочва във формат на две числа, следвани от десетична точка и след това още две цифри.
Всички транзакции, осъществявани по силата на Решение 2008/615/ПВР, се подават във формат 500 пиксела/инч или 19,68 пиксела/mm.
3.1.12.
В това 5-байтово поле се посочва номиналната резолюция на предаване на изпращаните изображения Резолюцията се изразява в пиксели/mm в същия формат като NSR (поле 1.011).
3.1.13.
В това незадължително поле се посочва наименованието на домейна за изпълнението на определения от потребителя логически запис тип-2. Състои се от две информационни единици и е „INT-I{US}4.22{GS}“.
3.1.14.
Това задължително поле предоставя механизъм за отразяване на датата и часа чрез универсалните единици в съответствие със средното време по Гринуич (GMT). Когато се използва полето GMT, в него се отразява тази универсална дата като допълнение към местната дата, дадена в поле 1.005 (DAT). С използването на полето GMT се премахват несъответствията в местното време, които се появяват, когато транзакцията и отговорът се предават между места, разделени от няколко часови зони. В полето GMT се посочва универсална дата и час в 24-часов формат, независимо от часовите зони. Изразява се във формат „CCYYMMDDHHMMSSZ“ — поредица от 15 символа, представляваща съчетанието от датата заедно с GMT и завършва със „Z“. Символите в поредицата „CCYY“ представляват годината на транзакцията, символите в поредицата „MM“ са стойностите на десетицата и единицата на месеца, а символите в поредицата „DD“ са стойностите на десетицата и единицата на деня от месеца, като символите в поредицата „HH“ представляват часа, „MM“ — минутата, а „SS“ — секундата. Пълната дата не може да има стойност по-висока от стойността на настоящата дата.
4. Логически запис тип-2: описателен текст
Структурата на по-голямата част от този запис не е дефинирана в първоначалния стандарт ANSI/NIST. Записът съдържа информация, която представлява специален интерес за службите, които изпращат или получават файла. За да е сигурно, че съответните дактилоскопични системи, между които се осъществява комуникацията, са съвместими, в записа е необходимо да се включат само изброените по-долу полета. В документа се посочва кои полета са задължителни и кои не са задължителни, като се дефинира и структурата на отделните полета.
4.1. Полета в логически запис тип-2:
4.1.1.
В това задължително поле се дава дължината на настоящия запис тип-2 и се посочва общият брой на байтовете, като се включват всички символи във всички полета на записа плюс разделителите.
4.1.2.
Това задължително поле съдържа символа за обозначение на изображението (IDC), представен в ASCII-формат за съответния IDC, определен в съдържанието на файла (CNT) на записа тип-1 (поле 1.003).
4.1.3.
Това поле е задължително и съдържа четири байта, с които се посочва на коя версия на INT-I съответства точно този запис тип-2.
Първите два байта посочват номера на основната версия, а вторите два — номера на подверсията. Например, в настоящия случай се работи по INT-I версия 4, редакция 22, което се изразява като „0422“.
4.1.4.
Този номер се задава от местната дактилоскопична служба за множеството следи, снети от едно местопрестъпление. Възприет е следният формат: CC/номер.
където „CC“ представлява кода на държавата по Интерпол, с дължина два буквено-цифрови символа, като номерът е съобразен с действащите на място указания и може да има дължина до 32 буквено-цифрови символа.
Това поле позволява на системата да идентифицира следи, които се свързват с определено местопрестъпление.
4.1.5.
Посочва се всяка поредица от следи в рамките на същия случай. Дължината му е до четири цифрови символа. Поредицата представлява следа или поредица от следи, които са обединени за целите на документирането и/или търсенето. Съгласно тази дефиниция, на отделните единични следи също ще трябва да се даде номер на поредица.
Това поле може да се включи заедно с MID (поле 2.009), за да се идентифицира конкретна следа в поредицата.
4.1.6.
Тук се посочва отделната следа в рамките на поредицата. Стойността представлява единична буква или две букви, като с „A“ се обозначава първата следа, с „B“ — втората и т.н. до „ZZ“. Това поле се използва аналогично на номера на поредицата следи, разгледан в описанието за SQN (поле 2.008).
4.1.7.
Това е уникален референтен номер, който се задава от национален орган за лице, срещу което за пръв път е повдигнато обвинение за извършено престъпление. В рамките на една страна едно лице не може никога да има повече от един референтен номер на правонарушител (CRN), нито да го поделя с друго лице. За едно и също лице обаче е възможно да има референтни номера на правонарушител в различни държави, които се разпознават по кода на съответната държава.
За полето CRN е възприет следният формат: CC/номер
където „CC“ представлява кода на държавата по Интерпол, с дължина два буквено-цифрови символа, като номерът е съобразен с действащите национални указания на издаващия орган и може да има дължина до 32 буквено-цифрови символа.
За транзакциите по силата на Решение 2008/615/ПВР това поле ще се използва за националния референтен номер на правонарушителя, зададен от службата по произход, който е свързан с изображенията в записите тип-4 и тип-15.
4.1.8.
В това поле се съдържа CRN (поле 2.010), изпратен чрез транзакция CPS или PMS без въвеждащия код за държавата.
4.1.9.
В това поле се съдържа CNO (поле 2.007), изпратен чрез транзакция MPS или MMS без въвеждащия код за държавата.
4.1.10.
В това поле се съдържа SQN (поле 2.008), изпратен чрез транзакция MPS или MMS.
4.1.11.
В това поле се съдържа MID (поле 2.009), изпратен чрез транзакция MPS или MMS.
4.1.12.
В случай на транзакция SRE във връзка с искане PMS, в това поле се дава информация за пръста, за който се отнася евентуалното попадение (HIT). Полето се попълва във формат:
NN където „NN“ е кодът на позицията на пръста, определен в таблица 5, с дължина две цифри.
Във всички останали случаи това поле не е задължително. Състои се от най-много 32 буквено-цифрови символа и в него може да се даде допълнителна информация относно искането.
4.1.13.
Това поле съдържа поне две подполета. В първото подполе се описва видът на извършеното търсене, като се използват трибуквени мнемонични съчетания, с които се определя типа транзакция в TOT (поле 1.004). Второто подполе съдържа само един символ. С „I“ се отбелязва наличие на попадение (HIT), а отсъствие на попадение (NOHIT) за търсения случай се отбелязва с „N“. В третото поле се съдържа идентификаторът на поредицата за кандидата за резултат и общият брой кандидати, разделени с наклонена черта. Ако кандидатите са повече от един, се отговаря с няколко съобщения. В случай на евентуално попадение (HIT) в четвъртото подполе се съдържа резултатът с дължина до шест символа.
Ако попадението (HIT) се потвърди, стойността на това подполе става „999999“.
Пример: „CPS{RS}I{RS}001/001{RS}999999{GS}“
Ако няма подаден резултат от отдалечената система AFIS, на съответното място се отбелязва нулев резултат.
4.1.14.
В това поле се съдържат съобщения за грешка в резултат на осъществена транзакция, които се изпращат на отправилата искането служба като част от транзакция за грешка.
Таблица 3: Съобщения за грешка
|
Numeric Code (1-3) |
Meaning (5-128) |
|
003 |
ERROR: UNAUTHORISED ACCESS |
|
101 |
Mandatory field missing |
|
102 |
Invalid record type |
|
103 |
Undefined field |
|
104 |
Exceed the maximum occurrence |
|
105 |
Invalid number of subfields |
|
106 |
Field length too short |
|
107 |
Field length too long |
|
108 |
Field is not a number as expected |
|
109 |
Field number value too small |
|
110 |
Field number value too big |
|
111 |
Invalid character |
|
112 |
Invalid date |
|
115 |
Invalid item value |
|
116 |
Invalid type of transaction |
|
117 |
Invalid record data |
|
201 |
ERROR: INVALID TCN |
|
501 |
ERROR: INSUFFICIENT FINGERPRINT QUALITY |
|
502 |
ERROR: MISSING FINGERPRINTS |
|
503 |
ERROR: FINGERPRINT SEQUENCE CHECK FAILED |
|
999 |
ERROR: ANY OTHER ERROR. FOR FURTHER DETAILS CALL DESTINATION AGENCY. |
Съобщения за грешка с номер между 100 и 199:
Тези съобщения за грешка са свързани с валидирането на ANSI/NIST записите и се определят като:
<error_code 1>: IDC <idc_number 1> FIELD <field_id 1> <dynamic text 1> LF
<error_code 2>: IDC <idc_number 2> FIELD <field_id 2> <dynamic text 2>...
където:
|
— |
error_code е код, зададен само за една определена причина (вж. таблица 3), |
|
— |
field_id е ANSI/NIST номерът на сгрешеното поле (напр. 001, 2.001, ...) в следния формат <record_type>.field_id>.sub_field_id>, |
|
— |
dynamic text е по-подробното описание на грешката, |
|
— |
LF означава „въвеждане на ред“ (Line Feed) и служи за разделяне на отделните грешки, когато има повече от една такава, |
|
— |
за запис тип-1 се определя ICD „-1“. |
Пример:
201: IDC - 1 FIELD 1.009 WRONG CONTROL CHARACTER {LF} 115: IDC 0 FIELD 2.003 INVALID SYSTEM INFORMATION
Това поле е задължително за транзакции за грешка.
4.1.15.
В това поле се съдържа максималният брой кандидати за верификация според отправилата искането служба. Стойността на ENC не може да надвишава стойностите, определени в таблица 11.
5. Логически запис тип-4: изображение с висока резолюция в сивата скала
Следва да се отбележи, че записите тип-4 са по-скоро бинарни, отколкото ASCII по характер. Поради това на всяко поле в записа се задава определено място, от което се подразбира, че всички полета са задължителни.
Стандартът позволява в записа да се опишат както размерът на изображението, така и резолюцията. Изискването за логическите записи тип-4 е да съдържат данни на дактилоскопично изображение, което се предава с номинална наситеност 500—520 пиксела на инч. За по-новата техника, предпочитаната резолюция е 500 пиксела на инч или 19,68 пиксела на милиметър. В INT-I е посочена наситеност от 500 пиксела на инч, освен когато сходни системи могат да си общуват с друга резолюция в рамките на зададените предпочитани стойности от 500—520 пиксела на инч.
5.1. Полета в логически запис тип-4:
5.1.1.
В това четирибайтово поле се дава дължината на настоящия запис тип-4 и се посочва общият брой на байтовете, като се включват всички байтове във всички полета на записа.
5.1.2.
Това е еднобайтовият бинарен израз на номера на IDC, който е даден в заглавния файл.
5.1.3.
Видът на отпечатъка е еднобайтово поле, което заема шестият байт на записа.
Таблица 4: Вид пръстов отпечатък
|
Code |
Description |
|
0 |
Live-scan of plain fingerprint |
|
1 |
Live-scan of rolled fingerprint |
|
2 |
Non-live scan impression of plain fingerprint captured from paper |
|
3 |
Non-live scan impression of rolled fingerprint captured from paper |
|
4 |
Latent impression captured directly |
|
5 |
Latent tracing |
|
6 |
Latent photo |
|
7 |
Latent lift |
|
8 |
Swipe |
|
9 |
Unknown |
5.1.4.
Това поле с фиксирана дължина от 6 байта заема позициите 7—12 на запис тип-4. В него се съдържат възможните пръстови позиции, като се започва от най-левия байт (7-ия байт на записа). Известната или най-вероятна пръстова позиция се взема от таблица 5. Възможно е да се посочат до пет допълнителни пръста, като пръстовите позициите се впишат в съответния порядък в оставащите пет байта, за което се използва същият формат. Ако се посочват по-малко от пет пръстови позиции, неизползваните байтове се запълват с бинарно 255. За рефериране на всички пръстови позиции се използва код „0“ със значение „неизвестно“.
Таблица 5: Код на пръстовите позиции и максимален размер
|
Finger position |
Finger code |
Width (mm) |
Length (mm) |
|
Unknown |
0 |
40,0 |
40,0 |
|
Right thumb |
1 |
45,0 |
40,0 |
|
Right index finger |
2 |
40,0 |
40,0 |
|
Right middle finger |
3 |
40,0 |
40,0 |
|
Right ring finger |
4 |
40,0 |
40,0 |
|
Right little finger |
5 |
33,0 |
40,0 |
|
Left thumb |
6 |
45,0 |
40,0 |
|
Left index finger |
7 |
40,0 |
40,0 |
|
Left middle finger |
8 |
40,0 |
40,0 |
|
Left ring finger |
9 |
40,0 |
40,0 |
|
Left little finger |
10 |
33,0 |
40,0 |
|
Plain right thumb |
11 |
30,0 |
55,0 |
|
Plain left thumb |
12 |
30,0 |
55,0 |
|
Plain right four fingers |
13 |
70,0 |
65,0 |
|
Plain left four fingers |
14 |
70,0 |
65,0 |
За следи, снети от местопрестъпление, се използват само кодовете от 0 до 10.
5.1.5.
Това еднобайтово поле заема 13-ия байт на запис тип-4. Ако съдържа „0“, това означава, че изображението е направено с препоръчителната резолюция от 19,68 пиксела/mm (500 пиксела/инч). Ако съдържа „1“, това означава, че изображението е направено с алтернативната резолюция за сканиране, посочена в запис тип-1.
5.1.6.
Това поле се намира на мястото на байтове 14—15 в запис тип-4. В него се посочва броят на пикселите, които се съдържат във всеки ред на сканираното изображение. Най-съществен е първият байт.
5.1.7.
В 16-17 байт на това поле е записан броят на редовете на сканираното изображение. Най-съществен е първият байт.
5.1.8.
В това еднобайтово поле се посочва алгоритъмът за компресиране в сивата скала, използван за кодиране на данните на изображението. За целите на прилагането, с бинарен код „1“ се посочва, че е използвана WSQ-компресия (допълнение 7).
5.1.9.
Това поле съдържа поредица от байтове, която представлява самото изображение. Структурата му очевидно зависи от използвания алгоритъм за компресиране.
6. Логически запис тип-9: запис на признаци (minutiae)
Записите тип-9 съдържат ASCII-текст, описващ признаците (minutiае) и свързана кодирана информация от следи. При транзакция за търсене на следи няма ограничение за тези записи тип-9 в рамките на един файл, но всеки от тях следва да се отнася за различен изглед или следа.
6.1. Извличане на признаци (minutiае)
6.1.1.
С този стандарт се определят три идентификационни номера, които се използват за описване на типа признак. Изброени са в таблица 6. Край на папиларна линия се означава като тип 1. Бифуркация се означава като тип 2. Ако даден признак не може да се определи ясно като един от горепосочените типове, той се означава като „друг“ („other“) — тип „0“.
Таблица 6: Типове признаци
|
Type |
Description |
|
0 |
Other |
|
1 |
Ridge ending |
|
2 |
Bifurcation |
6.1.2.
За да отговарят образците на раздел 5 от стандарта ANSI INCITS 378-2004, разположението (място и ъгъл на въртене) на отделния признак се описва по следния метод, който е усъвършенстван вариант на действащия стандарт INCITS 378-2004.
Позицията или местоположението на признака, който представлява край на папиларна линия, е точката на раздвояване на срединния скелет на междупапиларната бразда, разположена непосредствено пред края на папиларната линия. Ако трите отсечки на междупапиларната бразда се изтънят до скелет с широчина 1 пиксел, точката на пресичането им е местоположението на признака. Аналогично, местоположението на признака при бифуркация е точката на раздвояване на срединния скелет на папиларната линия. Ако всяка от трите отсечки на папиларната линия се изтъни до скелет с широчина 1 пиксел, точката на пресичане на трите отсечки е местоположението на признака.
След като всички краища на папиларни линии са преобразявани в бифуркации, всички признаци на дактилоскопичното изображение се представят под формата на бифуркации. Пикселовите координати X и Y на пресечната точка на трите отсечки на всеки признак могат да се форматират директно. Определянето на вектора на признака може да се извлече от всяка скелетна бифуркация. Трите отсечки на всяка скелетна бифуркация трябва да се разгледат и да се определи крайната точка на всяка отсечка. На фигура 6.1.2 са илюстрирани трите метода, които се използват за определяне на край на отсечка, което се прави на базата на сканираща резолюция 500 ppi.
Краят се установява според това кое събитие се прояви първо. Броят на пикселите се определя на базата на образ, сканиран с резолюция 500 ppi. Подразбира се, че при друга резолюция ще се използва различен брой пиксели.
|
— |
Разстояние от .064" (32-ри пиксел) |
|
— |
Краят на скелетната отсечка, която се появява в разстоянието между .02" и .064" (от 10-и до 32-ри пиксел); не се използват по-къси отсечки |
|
— |
Втора бифуркация е открита на разстояние .064" (преди 32-рия пиксел) |
Фигура 6.1.2

Ъгълът на признаците се определя, като се построят три виртуални лъча от точката на бифуркация до края на всяка отсечка. Ъглополовящата на най-малкия от трите ъгъла, образувани от лъчите, се използва за означаване на посоката на признака.
6.1.3.
За изразяване на признаците на пръстов отпечатък се използва Декартова координатна система. Местоположението на признаците се представя от техните х и у координати. Началото на координатната система е горният ляв ъгъл на оригиналното изображение, като х нараства надясно, а у нараства надолу. И двете координати (х и у) на признаците се изразяват в пиксел единици, отстоящи от началото. Следва да се отбележи, че началната точка и мерните единици не съответстват на общоприетата система, използвана за дефинициите на тип-9 в ANSI/NIST-ITL 1-2000.
6.1.4.
Ъглите се изразяват в стандартен математически формат, като нула градуса е вдясно и ъгълът расте обратно на часовниковата стрелка. Ъглите в записите са ориентирани по посоката на папиларната линия за край на папиларна линия и от центъра на междупапиларната бразда при бифуркация. Тази практика се разминава на 180 градуса със системата за определяне на ъглите, описана в дефинициите на тип-9 в ANSI/NIST-ITL 1-2000.
6.2. Полета в логически запис тип-9, формат INCITS-378
Всички полета от записите тип-9 се записват като ASCII текст. В този запис с тагови полета не се допускат бинарни полета.
6.2.1.
В това задължително ASCII поле се съдържа дължината на логическия запис — посочва се общият брой на байтовете, като се включват всички байтове във всички полета на записа.
6.2.2.
Това задължително двубайтово поле се използва за идентификация и описване на местоположението на данните за признаци. Записаният в това поле символ за IDC съответства на символа за IDC, който се намира в полето за съдържание на файла на записа тип-1.
6.2.3.
В това задължително еднобайтово поле се описва начинът, по който е получена информацията за дактилоскопичното изображение. ASCII стойността на самия код, която се взема от таблица 4, се вписва в това поле, за да се означи типът отпечатък.
6.2.4.
В това поле се съдържа „U“, за да се означи, че признаците са форматирани с M1-378. Въпреки че информацията може да е кодирана в съответствие със стандарта M1-378, всички полета за данни в записа тип-9 трябва да останат във формат ASCII-текст.
6.2.5.
В това поле се съдържат три информационни единици. Първата информационна единица има стойност „27“ (0x1B). Това е идентификацията на „притежателя“ на формáта CBEFF, определена от Международната асоциация на биометричната индустрия (IBIA) за Техническия комитет INCITS М1. Тази единица се отделя с разделителен символ <US> от типа формат CBEFF, на който се задава стойност „513“ (0x0201), за да се означи, че в този запис се съдържат само данни за местоположението и ъгловия вектор без информация за Extended Data Block. Тази единица се отделя с разделителен символ <US> от продуктовия идентификатор CBEFF (PID), с който се идентифицира „притежателят“ на кодиращото оборудване. Тази стойност се задава от фирмата производител. Стойността може да се вземе от уебсайта на IBIA (www.ibia.org), ако е публикувана там.
6.2.6.
В това поле има две информационни единици, разделени със символ <US>. Първата единица съдържа APPF, ако оборудването, използвано за добиване на първоначалния образ, има сертификат за съответствие с допълнение F (IAFIS Image Quality Specification, 29 януари, 1999 г.) по CJIS-RS-0010, спецификацията на Федералното бюро за разследване за изпращане на пръстови отпечатъци. Ако оборудването не отговаря на това изискване, се вписва стойност NONE. Втората информационна единица съдържа идентификацията на оборудването за „улавяне на образ“, която е продуктовият номер, зададен от фирмата-производител, за съответното оборудване. Стойност 0 показва, че идентификацията на оборудването за „улавяне на образ“ е неизвестна.
6.2.7.
В това задължително ASCII поле се съдържа броят на пикселите, които се съдържат в един хоризонтален ред на изпращаното изображение. Максималният размер на хоризонтален ред достига до 65 534 пиксела.
6.2.8.
В това задължително ASCII поле се задава броят на хоризонталните редове, които се съдържат в изпращаното изображение. Максималният размер на вертикален ред достига до 65 534 пиксела.
6.2.9.
В това задължително ASCII-поле се посочват единиците, използвани за описание на честотата на дискретизация на изображението (плътност на пикселите). В това поле стойност 1 показва броя на пикселите на 1 инч, а 2 показва пикселите на 1 сантиметър. Стойност 0 в това поле показва, че не е даден мащаб. В този случай съотношението на страните на пикселите се определя като коефициент HPS/VPS.
6.2.10.
В това задължително ASCII поле се задава числото на плътността на пикселите по хоризонталата, при условие че в полето SLC има вписана стойност 1 или 2. В останалите случаи тя показва хоризонталния компонент на съотношението на страните на пикселите.
6.2.11.
В това задължително ASCII поле се задава числото на плътността на пикселите по вертикалата, при условие че в полето SLC има вписана стойност 1 или 2. В останалите случаи тя показва вертикалния компонент на съотношението на страните на пикселите.
6.2.12.
В това задължително поле е даден номерът на изгледа на пръста, за който се отнасят данните в записа. Номерата на изгледите започват от 0 и нарастват с единица до 15.
6.2.13.
В това задължително поле се дава кодът, с който се означава позицията на пръста, от който е получена информацията в този запис тип-9. Позицията на пръста се посочва с код със стойности от 1 до 10, който се взема от таблица 5, а съответният код за позицията на длан се взема от таблица 10.
6.2.14.
Полето показва качеството на данните за признаците на пръстовия отпечатък като цяло и има стойност между 0 и 100. Това число е отражение на цялостното качество на записа за пръстовия отпечатък и представя качеството на оригиналното изображение, на извлечените признаци и всякакви допълнителни операции, които биха могли да повлияят на записа за признаците.
6.2.15.
В това задължително поле се съдържа броят на признаците, записани в този логически запис.
6.2.16.
В това поле има шест информационни единици, разделени със символ <US>. Състои се от няколко подполета, във всяко от които има подробни данни за един отделен признак. Общият брой на подполетата за признаци трябва да съответства на броя, посочен в поле 136. Първата информационна единица е индексният номер на признака, който започва от 1 и нараства с единица за всеки допълнителен признак на пръстовия отпечатък. Втората и третата информационна единица представляват „х“ и „у“ координатите на признаците, изразени в пиксели. Четвъртата информационна единица представлява ъгъла на признака, изразен в единици от по два градуса. Тази стойност е положително число между 0 и 179. Петата информационна единица изразява типа на признака. Със стойност 0 се представя тип „ДРУГО“ (OTHER), със стойност 1 се представя край на папиларна линия, а със стойност 2 — бифуркация на папиларната линия. Шестата информационна единица представлява качеството на съответния признак. Стойността ѝ варира между 1 за минималната стойност и 100 за максималната. Стойност 0 показва, че няма налична стойност за качеството. Всяко подполе се разделя от следващото с разделителен символ <RS>.
6.2.17.
Това поле се състои от поредица подполета, във всяко от които има по три информационни единици. Първата информационна единица на първото подполе показва начина на получаване на броя на папиларните линии. Стойност 0 показва, че не могат да се правят никакви заключения относно начина на получаване на броя на папиларните линии, нито относно реда, в който са дадени в записа. Стойност 1 показва, че за всеки център на признак са получени данни за броя на папиларните линии до най-близките съседни признаци в четири квадранта, като броят на папиларните линии за всеки център на признак са изброени заедно. Стойност 2 показва, че за всеки център на признак са получени данни за броя на папиларните линии до най-близките съседни признаци в осем октанта, като броят на папиларните линии за всеки център на признак са изброени заедно. И двете останали информационни единици от първото подполе са със стойност 0. Информационните единици се разделят с разделителен символ <US>. В следващите подполета се съдържа индексният номер на центъра на признака като първа информационна единица, индексният номер на съседния признак като втора информационна единица и броят на пресечените папиларни линии като трета информационна единица. Подполетата се разделят с разделителен символ <RS>.
6.2.18.
Това поле се състои от по едно подполе за всеки наличен център на папиларен образ в оригиналното изображение. Всяко подполе съдържа три информационни единици. Първите две единици съдържат позиционните „x“ и „y“ координати, изразени в пиксели. Третата информационна единица съдържа ъгловата стойност на центъра на папиларния образ, изразена в единици от по 2 градуса. Стойността е положително число между 0 и 179. При повече центрове на папиларни образи, същите се разделят с разделителен символ <RS>.
6.2.19.
Това поле се състои от по едно подполе за всяка налична делта в оригиналното изображение. Всяко подполе съдържа три информационни единици. Първите две единици съдържат позиционните „x“ и „y“ координати, изразени в пиксели. Третата информационна единица съдържа ъгловата стойност на делтата, изразена в единици от по 2 градуса. Стойността е положително число между 0 и 179. При повече центрове на папиларни образи, същите се разделят с разделителен символ <RS>.
7. Запис тип-13 на изображение на следи с променлива резолюция
Логическият запис тип-13 с тагови полета съдържа данни на изображение, получено от изображение на следи. Тези изображения са предназначени за изпращане на службите, които автоматично ще извлекат или ще осигурят интервенция на служители и обработка с цел получаване на желаната характеризираща информация от изображенията.
Под формата на тагови полета в записа се дава информация относно използваната резолюция на сканиране, размера на изображението и други параметри, необходими за обработката на изображението.
Таблица 7: Запис тип-13: изображение на следи с променлива резолюция
|
Ident |
Cond. code |
Field Number |
Field Name |
Char type |
Field size per occurrence |
Occur count |
Max byte count |
||
|
min. |
max. |
min |
max |
||||||
|
LEN |
M |
13.001 |
LOGICAL RECORD LENGTH |
N |
4 |
8 |
1 |
1 |
15 |
|
IDC |
M |
13.002 |
IMAGE DESIGNATION CHARACTER |
N |
2 |
5 |
1 |
1 |
12 |
|
IMP |
M |
13.003 |
IMPRESSION TYPE |
A |
2 |
2 |
1 |
1 |
9 |
|
SRC |
M |
13.004 |
SOURCE AGENCY/ORI |
AN |
6 |
35 |
1 |
1 |
42 |
|
LCD |
M |
13.005 |
LATENT CAPTURE DATE |
N |
9 |
9 |
1 |
1 |
16 |
|
HLL |
M |
13.006 |
HORIZONTAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
VLL |
M |
13.007 |
VERTICAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
SLC |
M |
13.008 |
SCALE UNITS |
N |
2 |
2 |
1 |
1 |
9 |
|
HPS |
M |
13.009 |
HORIZONTAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
VPS |
M |
13.010 |
VERTICAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
CGA |
M |
13.011 |
COMPRESSION ALGORITHM |
A |
5 |
7 |
1 |
1 |
14 |
|
BPX |
M |
13.012 |
BITS PER PIXEL |
N |
2 |
3 |
1 |
1 |
10 |
|
FGP |
M |
13.013 |
FINGER POSITION |
N |
2 |
3 |
1 |
6 |
25 |
|
RSV |
|
13.014 13.019 |
RESERVED FOR FUTURE DEFINITION |
— |
— |
— |
— |
— |
— |
|
COM |
O |
13.020 |
COMMENT |
A |
2 |
128 |
0 |
1 |
135 |
|
RSV |
|
13.021 13.199 |
RESERVED FOR FUTURE DEFINITION |
— |
— |
— |
— |
— |
— |
|
UDF |
O |
13.200 13.998 |
USER-DEFINED FIELDS |
— |
— |
— |
— |
— |
— |
|
DAT |
M |
13.999 |
IMAGE DATA |
B |
2 |
— |
1 |
1 |
— |
Легенда за вида символ: N = цифров; A = буквен; AN = буквено-цифров; B = бинарен
7.1. Полета в логически запис тип-13:
В следващите няколко параграфа са описани данните, които се съдържат във всяко от полетата в логически запис тип-13.
В логически запис тип-13 данните се въвеждат в номерирани полета. Изискването е първите две полета на записа да са подредени в установен ред, а полето, съдържащо данните на изображението е последното физическо поле в записа. В таблица 7 за всяко поле в запис тип-13 е посочен код за задължителност — задължително „M“ или незадължително „O“, номер на полето, наименование на полето, вид символ, размер на полето и колко пъти може да се използва. Използва се трицифрен номер на полето, като максималният брой на байтовете е даден в последната колонка. С увеличаване броя на цифрите в номера на полето се увеличава и максималният брой на байтовете. Двете стойности, които се вписват в „размер на полето за всяко използване“ се включват всички разделителни символи, използвани в полето. В „максималния брой байтове“ се включва номерът на полето, информацията и всички разделителни символи, в т.ч. и символът GS.
7.1.1.
В това задължително ASCII поле е записано числото на общия брой байтове в целия логически запис тип-13. В поле 13.001 се посочва дължината на записа, като се включват всички символи във всички полета на записа плюс разделителите.
7.1.2.
В това задължително ASCII поле се посочват данните за изображения на следи, които се съдържат в записа. Този IDC съответства на IDC, който се намира в полето за съдържание на файла (CNT) на записа тип-1.
7.1.3.
В това задължително еднобайтово или двубайтово ASCII поле се описва начинът, по който е получена информацията за изображението на следа. В това поле се вписва съответният код за следа, който се взема от таблица 4 (пръст) или от таблица 9 (длан).
7.1.4.
В това задължително ASCII поле се посочва идентификацията на службата или организацията, която първоначално е изготвила изображението на лице, което се съдържа в записа. В това поле обикновено се вписва идентификаторът на службата на произход (Originating Agency Identifier — ORI) за службата, която е изготвила изображението посредством „capture“ технология. Състои се от две информационни единици в следния формат: CC/служба.
Първата информационна единица съдържа кода на държавата по Интерпол — два буквено-цифрови символа. Втората единица, службата, представлява свободен текст за идентификация на службата — не повече от 32 буквено-цифрови символа.
7.1.5.
В това задължително ASCII поле се посочва датата, на която е изготвено изображението на следи, които се съдържат в записа. Датата се изписва с осем цифри във формат CCYYMMDD. Символите за CCYY представляват годината, в която е изготвено изображението; символите за MM представляват стойностите за десетицата и единицата на месеца; а символите за DD представляват стойностите за десетицата и единицата на деня от месеца; например 20000229 означава 29 февруари 2000 г. Пълната дата трябва да е действителна дата.
7.1.6.
В това задължително ASCII поле се задава броят на пикселите, които се съдържат в един хоризонтален ред на изпращаното изображение.
7.1.7.
В това задължително ASCII поле се задава броят на хоризонталните редове, които се съдържат в изпращаното изображение.
7.1.8.
В задължително ASCII-поле се посочват единиците, използвани за описание на честотата на дискретизация на изображението (плътност на пикселите). В това поле стойност 1 показва броя на пикселите на 1 инч, а 2 показва пикселите на 1 сантиметър. Стойност 0 в това поле показва, че не е даден мащаб. В този случай съотношението на страните на пикселите се определя като коефициент HPS/VPS.
7.1.9.
В това задължително ASCII поле се задава числото на плътността на пикселите по хоризонталата, при условие че в полето SLC има вписана стойност 1 или 2. В останалите случаи тя показва хоризонталния компонент на съотношението на страните на пикселите.
7.1.10.
В това задължително ASCII поле се задава числото на плътността на пикселите по вертикалата, при условие че в полето SLC има вписана стойност 1 или 2. В останалите случаи тя показва вертикалния компонент на съотношението на страните на пикселите.
7.1.11.
В това задължително ASCII поле се посочва алгоритъмът, използван за компресиране на изображения в сивата скала. Вижте в допълнение 7 кодовете за компресия.
7.1.12.
В това задължително ASCII поле се посочва броят на битовете, използвани за представяне на един пиксел. В това поле се вписва 8 за нормалните стойности на сивата скала от 0 до 255. Когато в това поле е въведена стойност, по-голяма от 8, това означава по-висока степен на пикселиране в сивата скала.
7.1.13.
В това задължително тагово поле се вписва позицията или позициите на пръста или дланта, които е възможно да съвпаднат с изображението на следата. Десетичното кодово число, което съответства на известната или най-вероятна пръстова позиция, се взема от таблица 5, а за най-вероятна позиция на дланта — от таблица 10, и се вписва като едносимволно или двусимволно ASCII подполе. Допълнителни позиции за пръст и/или длан могат да се посочат като се впишат алтернативните позиционни кодове под формата на подполета, отделени с разделителен символ RS. Кодът 0 — за „неизвестен пръст“, се използва за рефериране на всяка пръстова позиция от едно до десет. Кодът 20 — за „неизвестна длан“, се използва за рефериране на всяка вписана позиция на длан.
7.1.14.
Тези полета са резервирани за включване в по-нататъшни редакции на настоящия стандарт. Никое от тези полета не се използва на този етап на редактиране. Ако някое от тези полета е запълнено, то не се взема под внимание.
7.1.15.
Това незадължително поле може да се използва за вписване на бележки или на друга информация с ASCII-текст към данните за изображение на следи.
7.1.16.
Тези полета са резервирани за включване в по-нататъшни редакции на настоящия стандарт. Никое от тези полета не се използва на този етап на редактиране. Ако някое от тези полета е запълнено, то не се взема под внимание.
7.1.17.
Тези полета могат да се дефинират от потребителя и се използват за бъдещи изисквания. Размерът и съдържанието им се определят от потребителя и са съгласувани със службата получател. Когато са попълнени, в тях се съдържа информация под формата на ASCII текст.
7.1.18.
В това поле се намират всички данни на изображението на следа, направено посредством „capture“ технология. Полето винаги има стойност 999 и е последното физически разположено поле в записа. Например: след „13.999:“ има бинарно представени данни на изображение.
Всеки пиксел от некомпресирани данни в сивата скала обикновено се изразяват количествено в осем бита (256 нива на сивото), които се съдържат в един байт. Ако в BPX поле 13.012 е вписана стойност по-голяма или по-малка от 8, броят на байтовете, в които се съдържа един пиксел, е различен. Ако се използва компресия, пиксел-данните трябва да се компресират по начина, определен в полето GCA начин.
7.2. Край на запис тип-13: изображение на следи с променлива резолюция
За по-голяма прегледност, непосредствено след последния байт данни на поле 13.999 се поставя разделител FS, за да се раздели този от следващия логически запис. Този разделител трябва да се включи в полето за дължината на запис тип-13.
8. Запис тип-15: изображение на отпечатък от длан с променлива резолюция
Логически запис тип-15 с тагови полета съдържа и се използва за обмен на данни за изображение на отпечатък от длан, като в него има полета за фиксирана информация и за определена от потребителя информация, свързана с цифровизираното изображение. Под формата на тагови полета в записа се дава информация относно използваната резолюция на сканиране, размера на изображението и други параметри или бележки, необходими за обработката на изображението. Изпращаните на други служби изображения на длан се обработват от службите-получатели за извличане на желаната характеризираща информация, необходима за целите на сравняването.
Данните на изображението се получават пряко от субект, който използва уред за сканиране на живо или карта, на която е снет отпечатък на длан, или други носители, на които има отпечатък на длан.
Какъвто и да е методът за добиване на изображението на отпечатъка на длан, той трябва да има възможност за снемане на определен набор от изображения за всяка ръка. Този набор включва хипотенарната част на дланта, под формата на единично сканирано изображение, и пълната зона на изпънатата цяла длан от китката до върха на пръстите под формата на едно или две сканирани изображения. Ако са използвани две изображения за представяне на цялата длан, долното изображение показва дланта от китката до върха на междупръстието (ставата на третия пръст) и включва тенарната и хипотенарната област на дланта. Горното изображение обхваща зоната от долния край на междупръстието до върха на пръстите. По този начин се осигуряват достатъчно голяма зона на припокриване на двете изображения, и двете от които включват междупръстието на дланта. Чрез сравняване на папиларните линии и детайлите, които се съдържат в тази обща част, провеждащият изследването може да твърди с увереност, че двете изображения са на една и съща длан.
Тъй като транзакцията за отпечатък на длан може да се използва за различни цели, тя може да съдържа изображения на една или повече уникални зони на дланта или цялата ръка. Пълният набор от отпечатъци на дланта на едно лице обикновено включва хипотенарната част на дланта и изображение(я) на цялата длан от всяка ръка. Тъй като логическият запис с тагови полета, който се използва за изображение, може да съдържа само едно бинарно поле, за всяка хипотенарна част на длан ще е необходим отделен запис тип-15, както и едни или два записа тип-15 за всяка цяла длан. Поради това ще са необходими 4 — 6 записа тип-15 за представяне на отпечатъците от длан на даден субект в една нормална транзакция за отпечатъци на длан.
8.1. Полета в логически запис тип-15:
В следващите няколко абзаца са описани данните, които се съдържат във всяко от полетата в логически запис тип-15.
В логически запис тип-15 данните се въвеждат в номерирани полета. Изискването е първите две полета на записа да са подредени в установен ред, а полето с данните на изображението е последното физическо поле в записа. В таблица 8 за всяко поле в запис тип-15 е посочен код за задължителност — задължително „M“ или незадължително „O“, номер на полето, наименование на полето, вид символ, размер на полето и колко пъти може да се използва. Използва се трицифрен номер на полето, като максималният брой на байтовете е даден в последната колонка. С увеличаване броя на цифрите в номера на полето се увеличава и максималният брой на байтовете. Двете стойности, които се вписват в „размер на полето за всяко използване“. В „максималния брой байтове“ се включва номерът на полето, информацията и всички разделителни символи, в т.ч. и символът GS.
8.1.1.
В това задължително ASCII поле е записано числото на общия брой байтове в целия логически запис тип-15. В поле 15.001 се посочва дължината на записа, като се включват всички символи във всички полета на записа плюс разделителите.
8.1.2.
Това задължително ASCII поле се използва за идентифициране на изображението на отпечатък от длан, което се съдържа в записа. Този IDC съответства на IDC, който се намира в полето за съдържание на файла (CNT) на записа тип-1.
8.1.3.
В това задължително еднобайтово ASCII поле се посочва начинът, по който е получена информацията за изображението на отпечатъка на длан. В това поле се вписва съответният код, който се взема от таблица 9.
8.1.4.
В това задължително ASCII поле се вписва идентификацията на службата или организацията, която първоначално е изготвила изображението на лице, което се съдържа в записа. В това поле обикновено се вписва идентификаторът на службата на произход (ORI) за съответната служба, която е изготвила изображението посредством „capture“ технология. Състои се от две информационни единици в следния формат: CC/служба.
Първата информационна единица съдържа кода на държавата по Интерпол — два буквено-цифрови символа. Втората единица, службата, представлява свободен текст за идентификация на службата — не повече от 32 буквено-цифрови символа.
8.1.5.
В това задължително ASCII поле се вписва датата, на която е изготвено изображението на отпечатък от длан посредством capture-технология. Датата се изписва с осем цифри във формат CCYYMMDD. Символите за CCYY представляват годината, в която е изготвено изображението; символите за MM представляват стойностите за десетицата и единицата на месеца; а символите за DD представляват стойностите за десетицата и единиците на деня от месеца; например, вписаната стойност 20000229 означава 29 февруари 2000 г. Пълната дата трябва да е действително съществуваща дата.
8.1.6.
В това задължително ASCII поле се задава броят на пикселите, които се съдържат в един хоризонтален ред на изпращаното изображение.
8.1.7.
В това задължително ASCII поле се задава броят на хоризонталните редове, които се съдържат в изпращаното изображение.
8.1.8.
В задължително ASCII-поле се посочват единиците, използвани за описание на честотата на дискретизация на изображението (плътност на пикселите). В това поле стойност 1 показва броя на пикселите на 1 инч, а 2 показва пикселите на 1 сантиметър. Стойност 0 в това поле показва, че не е даден мащаб. В този случай съотношението на страните на пикселите се определя като коефициент HPS/VPS.
8.1.9.
В това задължително ASCII поле се задава числото на наситеност с пиксели по хоризонталата, при условие че в полето SLC има вписана стойност 1 или 2. В останалите случаи тя показва хоризонталния компонент на съотношението на страните на пикселите.
8.1.10.
В това задължително ASCII поле се задава числото на наситеност с пиксели по вертикалата, при условие че в полето SLC има вписана стойност 1 или 2. В останалите случаи тя показва вертикалния компонент на съотношението на страните на пикселите.
Таблица 8: Схема на запис тип-15 на изображение на отпечатък от длан с променлива резолюция
|
Ident |
Cond. code |
Field Number |
Field Name |
Char type |
Field size per occurrence |
Occur count |
Max byte count |
||
|
min. |
max. |
min |
max |
||||||
|
LEN |
M |
15.001 |
LOGICAL RECORD LENGTH |
N |
4 |
8 |
1 |
1 |
15 |
|
IDC |
M |
15.002 |
IMAGE DESIGNATION CHARACTER |
N |
2 |
5 |
1 |
1 |
12 |
|
IMP |
M |
15.003 |
IMPRESSION TYPE |
N |
2 |
2 |
1 |
1 |
9 |
|
SRC |
M |
15.004 |
SOURCE AGENCY/ORI |
AN |
6 |
35 |
1 |
1 |
42 |
|
PCD |
M |
15.005 |
PALMPRINT CAPTURE DATE |
N |
9 |
9 |
1 |
1 |
16 |
|
HLL |
M |
15.006 |
HORIZONTAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
VLL |
M |
15.007 |
VERTICAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
SLC |
M |
15.008 |
SCALE UNITS |
N |
2 |
2 |
1 |
1 |
9 |
|
HPS |
M |
15.009 |
HORIZONTAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
VPS |
M |
15.010 |
VERTICAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
CGA |
M |
15.011 |
COMPRESSION ALGORITHM |
AN |
5 |
7 |
1 |
1 |
14 |
|
BPX |
M |
15.012 |
BITS PER PIXEL |
N |
2 |
3 |
1 |
1 |
10 |
|
PLP |
M |
15.013 |
PALMPRINT POSITION |
N |
2 |
3 |
1 |
1 |
10 |
|
RSV |
|
15.014 15.019 |
RESERVED FOR FUTURE INCLUSION |
— |
— |
— |
— |
— |
— |
|
COM |
O |
15.020 |
COMMENT |
AN |
2 |
128 |
0 |
1 |
128 |
|
RSV |
|
15.021 15.199 |
RESERVED FOR FUTURE INCLUSION |
— |
— |
— |
— |
— |
— |
|
UDF |
O |
15.200 15.998 |
USER-DEFINED FIELDS |
— |
— |
— |
— |
— |
— |
|
DAT |
M |
15.999 |
IMAGE DATA |
B |
2 |
— |
1 |
1 |
— |
Таблица 9: Вид изображение на длан
|
Description |
Code |
|
Live-scan palm |
10 |
|
Nonlive-scan palm |
11 |
|
Latent palm impression |
12 |
|
Latent palm tracing |
13 |
|
Latent palm photo |
14 |
|
Latent palm lift |
15 |
8.1.11.
В това задължително ASCII поле се посочва алгоритъмът, използван за компресиране на изображения в сивата скала. Ако в полето е вписано „NONE“, това показва, че данните в този запис не са компресирани. За изображенията, които следва да се компресират, в това поле се вписва предпочитаният метод на компресиране за изображения с десет пръстови отпечатъка. Валидните кодове за компресията са дефинирани в допълнение 7.
8.1.12.
В това задължително ASCII поле се посочва броят на битовете, използвани за представяне на един пиксел. В това поле се вписва 8 за нормалните стойности на сивата скала от 0 до 255. Когато в това поле е въведена стойност, по-голяма или по-малка от 8, това означава съответно по-висока или по-ниска степен на пикселиране в сивата скала.
Таблица 10: Кодове, зони и размери на длан
|
Palm Position |
Palm code |
Image area (mm2) |
Width (mm) |
Height (mm) |
|
Unknown Palm |
20 |
28 387 |
139,7 |
203,2 |
|
Right Full Palm |
21 |
28 387 |
139,7 |
203,2 |
|
Right Writer s Palm |
22 |
5 645 |
44,5 |
127,0 |
|
Left Full Palm |
23 |
28 387 |
139,7 |
203,2 |
|
Left Writer s Palm |
24 |
5 645 |
44,5 |
127,0 |
|
Right Lower Palm |
25 |
19 516 |
139,7 |
139,7 |
|
Right Upper Palm |
26 |
19 516 |
139,7 |
139,7 |
|
Left Lower Palm |
27 |
19 516 |
139,7 |
139,7 |
|
Left Upper Palm |
28 |
19 516 |
139,7 |
139,7 |
|
Right Other |
29 |
28 387 |
139,7 |
203,2 |
|
Left Other |
30 |
28 387 |
139,7 |
203,2 |
8.1.13.
В това задължително тагово поле се описва позицията на отпечатъка от длан, съответстваща на изображението на отпечатъка от длан. Десетичният код, съответстващ на известната или най-вероятна позиция на отпечатъка от длан, се взема от таблица 10 и се вписва като двусимволно ASCII подполе. В таблица 10 също така са изброени максималните стойности за площта и размерите на изображението за всяка от възможните позиции на отпечатъка от длан.
8.1.14.
Тези полета са резервирани за включване в по-нататъшни редакции на настоящия стандарт. Никое от тези полета не се използва на този етап на редактиране. Ако някое от тези полета е запълнено, то не се взема под внимание.
8.1.15.
Това незадължително поле може да се използва за вписване на бележки или на друга информация с ASCII-текст към данните за изображение на отпечатък от длан.
8.1.16.
Тези полета са резервирани за включване в по-нататъшни редакции на настоящия стандарт. Никое от тези полета не се използва на този етап на редактиране. Ако някое от тези полета е запълнено, то не се взема под внимание.
8.1.17.
Тези полета могат да се дефинират от потребителя и се използват за бъдещи изисквания. Размерът и съдържанието им се определят от потребителя и са съгласувани със службата-получател. Когато са попълнени, в тях се съдържа информация под формата на ASCII-текст.
8.1.18.
В това поле се намират всички данни на изображението на отпечатък от длан, направено посредством capture-технология. Полето винаги има стойност 999 и е последното физически разположено поле в записа. Например: след „15.999:“ има бинарно представени данни на изображение. Всеки пиксел от некомпресирани данни в сивата скала обикновено се изразяват количествено в осем бита (256 нива на сивото), които се съдържат в един байт. Ако в BPX поле 15.012 е вписана стойност по-голяма или по-малка от 8, броят на байтовете, в които се съдържа един пиксел, е различен. Ако се използва компресия, пиксел-данните трябва да се компресират по начина, определен в полето CGA начин.
8.2. Край на запис тип-15 на изображение на отпечатък на длан с променлива резолюция
За по-голяма прегледност, непосредствено след последния байт данни на поле 15.999 се поставя разделител FS, за да се раздели този от следващия логически запис. Този разделител трябва да се включи в полето за дължината на запис тип-15.
8.3. Допълнителни записи тип-15: изображение на длан с променлива резолюция
Във файла могат да се включат допълнителни записи тип-15. За всяко допълнително изображение на отпечатък от длан е необходим цял логически запис тип-15 заедно със съответния FS разделител.
Таблица 11: Максимален допустим брой на кандидатите, които се подават за сверяване в едно съобщение
|
Type of AFIS Search |
TP/TP |
LT/TP |
LP/PP |
TP/UL |
LT/UL |
PP/ULP |
LP/ULP |
|
Maximum Number of Candidates |
1 |
10 |
5 |
5 |
5 |
5 |
5 |
Видове търсения:
|
|
TP/TP: десет пръстови отпечатъка спрямо десет пръстови отпечатъка (ten-print against tenprint) |
|
|
LT/TP: отпечатък от пръстови следи спрямо десет пръстови отпечатъка (fingerprint latent against ten-print) |
|
|
LP/PP: следи от отпечатък от длан спрямо отпечатък от длан (palmprint latent against palmprint) |
|
|
TP/UL: десет пръстови отпечатъка спрямо отпечатък от неопределена пръстова следа (ten-print against unsolved fingerprint latent) |
|
|
LT/UL: отпечатък от пръстова следа спрямо отпечатък от неопределена пръстова следа (fingerprint latent against unsolved fingerprint latent) |
|
|
PP/ULP: отпечатък от длан спрямо неопределен отпечатък от длан (palmprint against unsolved palmprint latent) |
|
|
LP/ULP: следа от отпечатък от длан спрямо неопределен отпечатък от длан (palmprint latent against unsolved palmprint latent) |
9. Допълнения към глава 2 (обмен на дактилоскопични данни)
9.1. Допълнение 1 ASCII разделителни кодове
|
ASCII |
Position (2) |
Description |
|
LF |
1/10 |
Separates error codes in field 2.074 |
|
FS |
1/12 |
Separates logical records of a file |
|
GS |
1/13 |
Separates fields of a logical record |
|
RS |
1/14 |
Separates the subfields of a record field |
|
US |
1/15 |
Separates individual information items of the field or subfield |
9.2. Допълнение 2 Изчисляване на буквено-цифровия контролен символ
За TCN и TCR (полета 1.09 и 1.10):
Числото, съответстващо на контролния символ, се генерира по следната формула:
(YY * 108 + SSSSSSSS) Modulo 23
където YY и SSSSSSSS са числовите стойности, съответстващи на последните две цифри от годината и на серийния номер.
Контролният символ се генерира по дадената по-долу справочна таблица.
За CRO (поле 2.010)
Числото, съответстващо на контролния символ, се генерира по следната формула:
(YY * 106 + NNNNNN) Modulo 23
където YY и NNNNNN са числовите стойности, съответстващи на последните две цифри от годината и на серийния номер.
Контролният символ се генерира по дадената по-долу справочна таблица.
Справочна таблица за контролните символи
|
1-A |
9-J |
17-T |
|
2-B |
10-K |
18-U |
|
3-C |
11-L |
19-V |
|
4-D |
12-M |
20-W |
|
5-E |
13-N |
21-X |
|
6-F |
14-P |
22-Y |
|
7-G |
15-Q |
0-Z |
|
8-H |
16-R |
|
9.3. Допълнение 3 Символни кодове
7-битов ANSI код за информационен обмен
|
ASCII Character Set |
||||||||||
|
+ |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
30 |
|
|
|
! |
" |
# |
$ |
% |
& |
’ |
|
40 |
( |
) |
* |
+ |
, |
— |
. |
/ |
0 |
1 |
|
50 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
|
60 |
< |
= |
> |
? |
@ |
A |
B |
C |
D |
E |
|
70 |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
|
80 |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
|
90 |
Z |
[ |
\ |
] |
^ |
_ |
` |
a |
b |
c |
|
100 |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
|
110 |
n |
o |
p |
q |
r |
s |
t |
u |
v |
w |
|
120 |
x |
y |
z |
{ |
| |
} |
~ |
|
|
|
9.4. Допълнение 4 Кратко описание на транзакция
Запис тип-1 (задължителен)
|
Identifier |
Field Number |
Field Name |
CPS/PMS |
SRE |
ERR |
|
LEN |
1.001 |
Logical Record Length |
M |
M |
M |
|
VER |
1.002 |
Version Number |
M |
M |
M |
|
CNT |
1.003 |
File Content |
M |
M |
M |
|
TOT |
1.004 |
Type of Transaction |
M |
M |
M |
|
DAT |
1.005 |
Date |
M |
M |
M |
|
PRY |
1.006 |
Priority |
M |
M |
M |
|
DAI |
1.007 |
Destination Agency |
M |
M |
M |
|
ORI |
1.008 |
Originating Agency |
M |
M |
M |
|
TCN |
1.009 |
Transaction Control Number |
M |
M |
M |
|
TCR |
1.010 |
Transaction Control Reference |
C |
M |
M |
|
NSR |
1.011 |
Native Scanning Resolution |
M |
M |
M |
|
NTR |
1.012 |
Nominal Transmitting Resolution |
M |
M |
M |
|
DOM |
1.013 |
Domain name |
M |
M |
M |
|
GMT |
1.014 |
Greenwich mean time |
M |
M |
M |
В колонката за задължителност:
O = незадължително; M = задължително; C = в зависимост от това дали транзакцията представлява отговор, изпратен до службата на произход
Запис тип-2 (задължителен)
|
Identifier |
Field Number |
Field Name |
CPS/PMS |
MPS/MMS |
SRE |
ERR |
|
LEN |
2.001 |
Logical Record Length |
M |
M |
M |
M |
|
IDC |
2.002 |
Image Designation Character |
M |
M |
M |
M |
|
SYS |
2.003 |
System Information |
M |
M |
M |
M |
|
CNO |
2.007 |
Case Number |
— |
M |
C |
— |
|
SQN |
2.008 |
Sequence Number |
— |
C |
C |
— |
|
MID |
2.009 |
Latent Identifier |
— |
C |
C |
— |
|
CRN |
2.010 |
Criminal Reference Number |
M |
— |
C |
— |
|
MN1 |
2.012 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
MN2 |
2.013 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
MN3 |
2.014 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
MN4 |
2.015 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
INF |
2.063 |
Additional Information |
O |
O |
O |
O |
|
RLS |
2.064 |
Respondents List |
— |
— |
M |
— |
|
ERM |
2.074 |
Status/Error Message Field |
— |
— |
— |
M |
|
ENC |
2.320 |
Expected Number of Candidates |
M |
M |
— |
— |
В колонката за задължителност:
O.= незадължително; M = задължително; C = в зависимост от това дали има налични данни
|
* |
= |
ако предаването на данните е в съответствие с националното законодателство (не попада в обхвата на Решение 2008/615/ПВР) |
9.5. Допълнение 5 Дефиниции на запис тип-1:
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
1.001 |
Logical Record Length |
N |
1.001:230{GS} |
|
VER |
M |
1.002 |
Version Number |
N |
1.002:0300{GS} |
|
CNT |
M |
1.003 |
File Content |
N |
1.003:1{US}15{RS}2{US}00{RS}4{US}01{RS}4{US}02{RS}4{US}03{RS}4{US}04{RS}4{US}05{RS}4{US}06{RS}4{US}07{RS}4{US}08{RS}4{US}09{RS}4{US}10{RS}4{US}11{RS}4{US}12{RS}4{US}13{RS}4{US}14{GS} |
|
TOT |
M |
1.004 |
Type of Transaction |
A |
1.004:CPS{GS} |
|
DAT |
M |
1.005 |
Date |
N |
1.005:20050101{GS} |
|
PRY |
M |
1.006 |
Priority |
N |
1.006:4{GS} |
|
DAI |
M |
1.007 |
Destination Agency |
1* |
1.007:DE/BKA{GS} |
|
ORI |
M |
1.008 |
Originating Agency |
1* |
1.008:NL/NAFIS{GS} |
|
TCN |
M |
1.009 |
Transaction Control Number |
AN |
1.009:0200000004F{GS} |
|
TCR |
C |
1.010 |
Transaction Control Reference |
AN |
1.010:0200000004F{GS} |
|
NSR |
M |
1.011 |
Native Scanning Resolution |
AN |
1.011:19.68{GS} |
|
NTR |
M |
1.012 |
Nominal Transmitting Resolution |
AN |
1.012:19.68{GS} |
|
DOM |
M |
1.013 |
Domain Name |
AN |
1.013: INT-I{US}4.22{GS} |
|
GMT |
M |
1.014 |
Greenwich Mean Time |
AN |
1.014:20050101125959Z |
В колонката за задължителност: O = незадължително, M = задължително, C = под условие
В колонката за вид символ: A = буквен, N = числов, B = бинарен
1* допустими символи за наименованието на службата [„0..9“, „A..Z“, „a..z“, „_“, „.“, „“, „—“]
9.6. Допълнение 6 Запис тип-2: дефиниции
Таблица А.6.1: Транзакции CPS и PMS
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
CRN |
M |
2.010 |
Criminal Reference Number |
AN |
2.010:DE/E999999999{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
ENC |
M |
2.320 |
Expected Number of Candidates |
N |
2.320:1{GS} |
Таблица А.6.2: Транзакция SRE
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
CRN |
C |
2.010 |
Criminal Reference Number |
AN |
2.010:NL/2222222222{GS} |
|
MN1 |
C |
2.012 |
Miscellaneous Identification Number |
AN |
2.012:E999999999{GS} |
|
MN2 |
C |
2.013 |
Miscellaneous Identification Number |
AN |
2.013:E999999999{GS} |
|
MN3 |
C |
2.014 |
Miscellaneous Identification Number |
N |
2.014:0001{GS} |
|
MN4 |
C |
2.015 |
Miscellaneous Identification Number |
A |
2.015:A{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
RLS |
M |
2.064 |
Respondents List |
AN |
2.064:CPS{RS}I{RS}001/001{RS}999999{GS} |
Таблица А.6.3: Транзакция ERR
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
MN1 |
M |
2.012 |
Miscellaneous Identification Number |
AN |
2.012:E999999999{GS} |
|
MN2 |
C |
2.013 |
Miscellaneous Identification Number |
AN |
2.013:E999999999{GS} |
|
MN3 |
C |
2.014 |
Miscellaneous Identification Number |
N |
2.014:0001{GS} |
|
MN4 |
C |
2.015 |
Miscellaneous Identification Number |
A |
2.015:A{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
ERM |
M |
2.074 |
Status/Error Message Field |
AN |
2.074: 201: IDC - 1 FIELD 1.009 WRONG CONTROL CHARACTER {LF} 115: IDC 0 FIELD 2.003 INVALID SYSTEM INFORMATION {GS} |
Таблица А.6.4: Транзакции MPS и MMS
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
CNO |
M |
2.007 |
Case Number |
AN |
2.007:E999999999{GS} |
|
SQN |
C |
2.008 |
Sequence Number |
N |
2.008:0001{GS} |
|
MID |
C |
2.009 |
Latent Identifier |
A |
2.009:A{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
ENC |
M |
2.320 |
Expected Number of Candidates |
N |
2.320:1{GS} |
В колонката за задължителност: O = незадължително, M = задължително, C = под условие
В колонката за вид символ: A = буквен, N = числов, B = бинарен
1* допустимите символи са [„0..9“, „A..Z“, „a..z“, „_“, „.“, „“, „—“]
9.7. Допълнение 7 Кодове за компресия в сивата скала
Кодове за компресия
|
Compression |
Value |
Remarks |
|
Wavelet Scalar Quantization Grayscale Fingerprint Image Compression Specification IAFIS-IC-0010(V3), dated December 19, 1997 |
WSQ |
Algorithm to be used for the compression of grayscale images in Type-4, Type-7 and Type-13 to Type-15 records. Shall not be used for resolutions > 500 dpi. |
|
JPEG 2000 [ISO 15444/ITU T.800] |
J2K |
To be used for lossy and losslessly compression of grayscale images in Type-13 to Type-15 records. Strongly recommended for resolutions > 500 dpi. |
9.8. Допълнение 8 Спецификация на съобщенията
За подобряване на вътрешните работни процеси, в полето „Предмет“ на транзакциите, осъществявани по линия на Прюм, трябва да се попълнят кодът (CC) на държавата-членка, която изпраща съобщението, и типът на транзакцията (ТОТ поле 1.004)
Формат: CC/тип транзакция
Пример: „DE/CPS“
Съобщението може да бъде без съдържание.
ГЛАВА 3: Обмен на данни за регистрацията на превозни средства
1. Общ набор от данни за автоматизирано търсене на данни за регистрацията на превозни средства
1.1. Определения
Определенията за задължителните елементи и незадължителните елементи на данните, посочени в член 16, параграф 4, са следните:
Задължително (M):
Този елемент трябва да бъде съобщен, когато има налична информация в националния регистър на държавата-членка. Следователно информацията се обменя задължително, когато е налична.
Незадължително (O):
Този елемент може да бъде съобщен, когато има налична информация в националния регистър на държавата-членка. Следователно не е задължително да се обменя информация, дори когато тя е налична.
Всеки елемент от набора данни се обозначава с (Y), когато този елемент се определя като особено важен във връзка с Решение 2008/615/ПВР.
1.2. Търсене на превозно средство/собственик/ползвател
1.2.1.
Съществуват два различни начина за търсене на информацията, които са определени по-долу:
|
— |
по номер на шасито (VIN), референтна дата и час (незадължително); |
|
— |
по табела с регистрационния номер, по номер на шасито (VIN) (незадължително), референтна дата и час (незадължително). |
Посредством тези критерии за търсене се получава информация, свързана с едно, а понякога и повече превозни средства. Ако се получи информация само за едно превозно средство, всички единици информация се поместват в един отговор. Ако са намерени повече превозни средства, държавата-членка, към която е отправено искането, може да определи кои информационни единици да изпрати в отговора — всички единици или само единиците, с които да се усъвършенства търсенето (напр. поради съображения, свързани с неприкосновеността на личния живот, или съображения за качество на работата).
Информационните единици, необходими за усъвършенстване на търсенето, са дадени в точка 1.2.2.1. В точка 1.2.2.2 е описана изчерпателно цялата информация.
Когато се прави търсене по номер на шаси, референтна дата и час, то може да се направи в една от участващите държави-членки или във всичките.
Когато се прави търсене по номер на свидетелство за управление, референтна дата и час, то трябва да се направи в една конкретна държава-членка.
Обикновено за търсене се използват датата и часът към момента, но е възможно да се извърши търсене с референтна дата и час в миналото. Когато се извършва търсене по референтна дата и час в миналото, а историческа информация не е налична в регистъра на съответната държава-членка, понеже такава регистрирана информация отсъства, информацията може да се изпрати, като се посочи, че тази информация е информация към момента.
1.2.2.
|
1.2.2.1. |
Данни, които се дават в отговора с цел прецизиране на търсенето
|
|
1.2.2.2. |
Пълен набор от данни
|
2. Сигурност на данните
2.1. Обзорен преглед
Софтуерното приложение EUCARIS се използва за защитена комуникация с другите държави-членки и за съобщения, подавани в XML-формат обратно към „наследените“ системи на държавите-членки. Държавите-членки обменят съобщения, като ги изпращат директно на получателя. Центърът за електронни данни на държавата-членка е свързан с мрежата TESTA на ЕС.
По мрежата се изпращат криптирани съобщения в XML-формат. За криптиране на съобщенията се използва методът SSL. Съобщенията, които се връщат обратно, са в обикновен текстови XML-формат, тъй като връзката между приложението и т.нар. „back-end“ става в защитена среда.
Осигурено е клиентско програмно приложение, което се използва в държавата-членка за търсене в собствения ѝ регистър или в регистрите на другите държави-членки. Клиентите се идентифицират посредством потребителско име за идентификация/парола или клиентски сертификат. Връзката с потребителя може да е криптирана, но това е задължение на всяка отделна държава-членка.
2.2. Характеристики на сигурността, свързани с обмена на съобщения
Сигурността е проектирана на основата на съчетание от HTTPS и XML-подпис. При този вариант се използва XML-подпис за подписване на всички съобщения, които се изпращат до сървъра, като чрез проверка на подписа се удостоверява кой е подателят на съобщението. Едностранен SSL (само сертификат на сървъра) се използва за защита на поверителността и целостта на съобщението по време на изпращане и се осигурява защита от атаки с цел изтриване/„прослушване“ или вмъкване. Вместо първоначално предвидената разработка на софтуер за внедряване на двустранен SSL, беше внедрен XML-подпис. Използването на XML-подпис се доближава повече до пътната карта на уебуслугите отколкото двустранният SSL и следователно е по-стратегическо решение.
XML-подписът може да се внедри по няколко начина, но избраният подход е да се използва XML-подпис като част от сигурността на услугите в глобалната мрежа (WSS). В WSS се уточнява как да се използва XML-подписът. Тъй като WSS е разработен на основата на стандарта SOAP, логично е да спазваме възможно най-точно стандарта SOAP.
2.3. Характеристики на сигурността, несвързани с обмена на съобщения
2.3.1.
Автентикацията на потребителите на уебприложението Eucaris се осъществява посредством потребителско име и парола. Тъй като се използва стандартната автентикация на Windows, държавите-членки могат при необходимост да увеличат степента на автентикация на потребителите, като използват клиентски сертификати.
2.3.2.
Софтуерното приложение на Eucaris поддържа различни потребителски функции. За всяка категория услуги се получава отделно разрешение — напр. потребители (с изключителни права) на функционалността „Договор за Eucaris“ нямат право да използват функционалността „Прюм“. Услугите по администрирането са отделени от обичайните функции на крайния потребител.
2.3.3.
Регистрирането на всички видове съобщения е улеснено от софтуерното приложение Eucaris. Посредством една от функциите за администриране националният администратор може да установи кои съобщения са регистрирани: искания от крайни потребители, входящи искания от други държави-членки, информация, предоставяна от национални регистри и т.н.
Приложението може да се конфигурира при това регистриране да използва вътрешна база данни или външна база данни (Oracle). Ясно е, че решението за това какви съобщения да се регистрират зависи от съоръженията за тази цел на други места — в „наследените“ системи, и от това с какви клиентски приложения има връзка.
В заглавната част на всяко съобщение се съдържа информация за отправилата искането държава-членка, съответната организация в държавата-членка и крайния потребител. Посочва се и поводът за отправяне на искането.
Посредством комбинираното регистриране в двете държави — отправилата искането и отговарящата — е възможно да се проследи напълно всеки обмен на съобщения (напр. по искане на замесено лице).
Регистрирането се потвърждава чрез уебклиента на Eucaris (меню Administration, Logging configuration). Функционалността за регистрирането се изпълнява от централната система. Когато е активирана функцията за регистриране, цялото съобщение (заглавна и съдържателна част) се съхранява в един регистърен запис. Възможно е да се зададе ниво на регистриране за определена услуга и за вид съобщения.
Нива на регистриране
Възможни са следните нива на регистриране:
Private — регистриране на съобщение: Регистрирането НЕ е достъпно за регистърната услуга за извличане, но е достъпно само на национално равнище, за одитиране и решаване на проблеми.
None — съобщението не се регистрира.
Видове съобщения
В информационния обмен между държавите-членки се включват различни видове съобщения, които са представени схематично по-долу.
Възможните видове съобщения (в показаната на фигурата централна система Eucaris за държавата-членка Х) са:
|
1. |
Request to Core System_Request message by Client |
|
2. |
Request to Other Member State_Request message by Core System of this Member State |
|
3. |
Request to Core System of this Member State_Request message by Core System of other Member State |
|
4. |
Request to Legacy Register_Request message by Core System |
|
5. |
Request to Core System_Request message by Legacy Register |
|
6. |
Response from Core System_Request message by Client |
|
7. |
Response from Other Member State_Request message by Core System of this Member State |
|
8. |
Response from Core System of this Member State_Request message by other Member State |
|
9. |
Response from Legacy Register_Request message by Core System |
|
10. |
Response from Core System_Request message by Legacy Register Следните видове информационен обмен са показани на фигурата:
|
Фигура: Видове съобщения за регистриране
2.3.4.
Не се използва хардуерен модул за сигурност.
Хардуерният модул за сигурност (HSM) осигурява добра защита на ключа, който се използва за подписване на съобщенията и идентифициране на сървърите. С това се допълва цялостното ниво на сигурност, на HSM представлява висок разход за покупка/поддръжка и няма изискване за това какво решение да се вземе — за FIPS 140-2 ниво 2 или ниво 3 HSM Тъй като се използва затворена мрежа, при която заплахите се овладяват ефективно, решението е първоначално да не се използва хардуерен модул за сигурност (HSM). Ако се появи необходимост от хардуерен модул за сигурност (HSM), напр. с цел акредитация, той може да се добави към архитектурата.
3. Технически условия на обмена на данните
3.1. Общо описание на приложението EUCARIS
3.1.1.
Софтуерното приложение EUCARIS свързва всички участващи държави-членки в мрежа, в която всяка държава-членка комуникира директно с друга държава-членка. За установяване на комуникацията не е необходим централен компонент. Приложението EUCARIS се използва за защитена комуникация с другите държави-членки и за съобщения, подавани в XML-формат обратно към „наследените“ системи на държавите-членки. Тази архитектура е показана на схемата по-долу.

Държавите-членки обменят съобщения, като ги изпращат директно на получателя. Центърът за електронни данни на държавата-членка е свързан с мрежата, която се използва за обмен на съобщенията (TESTA). Държавите-членки получават достъп до мрежата TESTA посредством националния си портал за достъп до мрежата TESTA. За връзката с мрежата е необходимо да се използва firewall, а приложението Eucaris да е свързано чрез рутер с този firewall. В зависимост от избрания вариант за защита на съобщенията, се използва сертификат или от рутера, или от приложението Eucaris.
Осигурено е клиентско програмно приложение, което се използва в дадена държава-членка за търсене в собствения ѝ регистър или в регистрите на други държави-членки. Клиентското приложение се свързва с Eucaris. Клиентите се идентифицират посредством потребителско име за идентификация/парола или клиентски сертификат. Връзката с потребител във външна организация (напр. полицейска служба) може да е криптирана, но това е задължение на всяка отделна държава-членка.
3.1.2.
Обхватът на системата Eucaris се ограничава до процесите, които участват в обмена на информация между органите, отговарящи за регистрацията в държавите-членки, и основните правила за представянето на тази информация. Процедурите и автоматизираните процеси, в които се използва тази информация, са извън обхвата на системата.
Държавите-членки могат да изберат да използват функционалността „Eucaris клиент“ или да си направят собствено клиентско приложение. В таблицата по-долу е описано кои аспекти на системата Eucaris се използват задължително и/или се препоръчват и кои не е задължително да се използват и/или се определят по преценка на държавата-членка.
|
EUCARIS aspects |
M/O (9) |
Remark |
||||||||||||||||
|
Network concept |
M |
The concept is an „any-to-any“ communication. |
||||||||||||||||
|
Physical network |
M |
TESTA |
||||||||||||||||
|
Core application |
M |
The core application of EUCARIS has to be used to connect to the other Member States. The following functionality is offered by the core:
|
||||||||||||||||
|
Client application |
O |
In addition to the core application the EUCARIS II client application can be used by a Member State. When applicable, the core and client application are modified under auspices of the EUCARIS organisation. |
||||||||||||||||
|
Security concept |
M |
The concept is based on XML-signing by means of client certificates and SSL-encryption by means of service certificates. |
||||||||||||||||
|
Message specifications |
M |
Every Member State has to comply with the message specifications as set by the EUCARIS organisation and this Council Decision. The specifications can only be changed by the EUCARIS organisation in consultation with the Member States. |
||||||||||||||||
|
Operation and Support |
M |
The acceptance of new Member States or a new functionality is under auspices of the EUCARIS organisation. Monitoring and help desk functions are managed centrally by an appointed Member State. |
3.2. Функционални и нефункционални изисквания
3.2.1.
В този раздел се прави общо описание на общите функции.
|
№ |
Описание |
|
1. |
Системата позволява на регистрационните органите на държавите-членки да обменят съобщения с искания и отговори по интерактивен начин. |
|
2. |
Системата съдържа клиентско приложение, което позволява на крайните потребители да изпращат исканията си и да предоставят в отговор информация за ръчна обработка. |
|
3. |
Системата способства „оповестяването“, което позволява на една държава-членка да изпрати искане до всички останали държави-членки. Входящите отговори са консолидирани от централното приложение в едно съобщение отговор до клиентското приложение (тази функционалност се нарича запитване до множество страни) |
|
4. |
Системата е способна да работи с различни видове съобщения. Потребителските функции, разрешенията, маршрутизацията, подписването и регистрирането са определени поотделно за всяка категория услуги. |
|
5. |
Системата позволява на държавите членки да обменят съобщения на партиди или съобщения, които се състоят от голям брой искания или отговори. Тези съобщения се обработват асинхронно. |
|
6. |
Системата подрежда хронологично асинхронните съобщения с цел изчакване, ако получаващата държава-членка е временно неспособна да ги приеме, и гарантира доставянето им веднага след като получателят е отново на линия. |
|
7. |
Системата съхранява входящите асинхронни съобщения до момента, в който стане възможно те да бъдат обработени. |
|
8. |
Системата дава достъп единствено до приложенията Eucaris на останалите държави-членки, а не на отделни организации в рамките на тези държави-членки, т.е. всеки регистрационен орган действа като единствен портал между крайните потребители в своята държава и съответните органи в другите държави-членки. |
|
9. |
Възможно е за един Eucaris-сървър да се определят потребители от различни държави-членки, на които да се дават разрешения съгласно правата, определени в тази държава-членка. |
|
10. |
В съобщенията се дава информация за отправилата искането държава-членка и организация, както и за крайния потребител. |
|
11. |
Системата способства регистрирането на обмена на съобщения между различните държави-членки и между централното приложение и националните регистрационни системи. |
|
12. |
Системата позволява назначеният секретар — специално определена за целта организация или държава-членка — да събира регистрираната информация за съобщенията, изпратени/получени от всички участващи държави-членки с цел изготвяне на статистически отчети. |
|
13. |
Всяка държава-членка посочва самостоятелно каква регистрирана информация е предоставена на разположение на секретаря и коя информация е „само за вътрешно ползване“. |
|
14. |
Системата позволява на националните администратори на всяка държава-членка да извличат полезна статистика. |
|
15. |
Системата позволява да се добавят нови държави-членки посредством изпълнение на елементарни административни задачи. |
3.2.2.
|
№ |
Описание |
|
16. |
Системата предоставя интерфейс за автоматизирана обработка на съобщения от back-end/„наследени“ системи и позволява интегрирането на потребителския интерфейс в тези системи (customised user-interface) |
|
17. |
Системата се разбира и се усвоява лесно, като има и включени инструкции за работа в текстови формат (help-text). |
|
18. |
Системата разполага с достатъчно документация, с която подпомага държавите-членки при интегрирането, експлоатацията и поддръжката ѝ (напр. справочници, документация за функционалността и техническите характеристики, ръководство за работа и т.н.). |
|
19. |
Интерфейсът за потребителите е многоезичен и предлага възможност на крайния потребител да избере предпочитания от него език. |
|
20. |
Интерфейсът за потребителите включва компонент, чрез който местният администратор може да преведе на съответния национален език както информацията на екрана, така и кодираната информация. |
3.2.3.
|
№ |
Описание |
|
21. |
Системата е предназначена да работи като сигурна и надеждна операционна система, която е толерантна към грешките на работещите с нея и която се възстановява напълно след прекъсване на електроенергията и други аварии. Системата трябва да може да се рестартира с минимални или нулеви загуби на данни. |
|
22. |
Системата трябва да дава стабилни и възпроизводими резултати. |
|
23. |
Системата е предназначена да работи надеждно. Възможно е системата да се внедри в конфигурация, която гарантира степен на наличност 98 % (чрез повторяемост, използване на резервни (back-up) сървъри и т.н.) при всяка двустранна комуникация. |
|
24. |
Системата може да се използва частично дори при неизправност на някои компоненти (ако има авария в държавата-членка С, комуникацията между държавите-членки А и B не се прекъсва). Броят на единичните точки, в които повредата може да доведе до прекъсване на информационната верига, следва да се сведе до минимум. |
|
25. |
Времето за възстановяване след сериозна повреда следва да е по-малко от един ден. Времето, в което системата не работи, би трябвало да може да се намали максимално чрез дистанционно обслужване, напр. от център за обслужване. |
3.2.4.
|
№ |
Описание |
|
26. |
Системата може да се използва 24 часа 7 дни в седмицата. Същият времеви диапазон (24 x 7) следователно се изисква и за „наследените“ системи на държавите-членки. |
|
27. |
Системата реагира бързо на потребителските искания независимо от извършваните „на заден план“ дейности. Същото изискване се отнася и за „наследените“ системи на страните, за да се осигури срок за реагиране в допустимите граници. Допустимият срок за реагиране на единично искане е максимум 10 секунди. |
|
28. |
Системата е проектирана за работа с множество потребители по начин, който позволява на извършваните „на заден план“ дейности да продължават докато потребителят работи „на преден план“. |
|
29. |
Системата е проектирана за мащабируемост, за да може да поддържа потенциалното увеличение на броя съобщения, когато се добавят нова функционалност или нови организации или държави-членки. |
3.2.5.
|
№ |
Описание |
|
30. |
Системата е пригодена (напр. като мерки за сигурност) за обмен на съобщения, в които се съдържат чувствителни лични данни, свързани с неприкосновеността на личния живот (напр. собственици/ползватели на коли), класифицирана като информация за ограничено ползване в ЕС. |
|
31. |
Системата се поддържа по начин, при който не се допуска неразрешен достъп до данните. |
|
32. |
Системата включва услуга за управлението на правата и разрешенията на националните крайни потребители. |
|
33. |
На държавите-членки е осигурена възможност да проверяват самоличността на подателя (на равнище държава-членка) посредством XML-подпис. |
|
34. |
Държавите-членки трябва изрично да разрешат на друга държава-членка да иска конкретна информация. |
|
35. |
Системата предоставя на ниво приложение политика за пълна сигурност и криптиране, които са съвместими с нивото на сигурност, изисквано в подобни ситуации. В такива случаи неприкосновеността и целостта на информацията се гарантират чрез използването на XML-подписи и криптиране чрез SSL-тунелиране. |
|
36. |
Всеки обмен на съобщения може да се проследи посредством регистрирането. |
|
37. |
Предоставена е защита срещу атаки за изтриване (изтриване на съобщение от трето лице) и „прослушване“ или вмъкване („прослушване“ или изтриване на съобщение от трето лице). |
|
38. |
Системата използва сертификати на „доверени трети лица“ (TTP). |
|
39. |
Системата е способна да работи с различните сертификати на съответните държави-членки, в зависимост от вида на съобщението или услугата. |
|
40. |
Мерките за сигурност на ниво приложение са достатъчни, за да се осигури възможност за работа с неакредитирани мрежи. |
|
41. |
Системата е в състояние да използва основни техники за сигурност — напр. XML-firewall. |
3.2.6.
|
№ |
Описание |
|
42. |
Системата може да се разширява, като се добавят нови видове съобщения и нова функционалност. Разходите за адаптиране са минимални поради централизираната разработка на компонентите на приложението. |
|
43. |
Държавите-членки са в състояние да дефинират нови видове съобщения за двустранно използване. Не се налага всички държави-членки да поддържат всички видове съобщения. |
3.2.7.
|
№ |
Описание |
|
44. |
Системата предоставя механизми за мониторинг от страна на централна служба и/или оператори по отношение на мрежата и сървърите в различните държави-членки. |
|
45. |
Системата предоставя механизми за дистанционно обслужване от централно бюро за обслужване. |
|
46. |
Системата предоставя механизми за анализ на проблемите. |
|
47. |
Системата може да се разширява, за да обхваща нови държави-членки. |
|
48. |
Приложението може лесно да се инсталира от служители с минимална квалификация и опит в областта на ИТ. Процедурата за инсталиране е автоматизирана във възможно най-голяма степен. |
|
49. |
Системата предоставя постоянна среда за провеждане на изпитвания и приемане на нови схеми. |
|
50. |
Годишните разходи за обслужване и поддръжка са намалени максимално чрез съобразяване с пазарните стандарти, като приложението е разработено по начин, който изисква възможно най-малко централно обслужване. |
3.2.8.
|
№ |
Описание |
|
51. |
Системата е предназначена за продължителен експлоатационен срок и разполага със съответната документация. |
|
52. |
Системата е проектирана да работи независимо от доставчика на мрежови услуги. |
|
53. |
Системата е съвместима с действащите в държавите-членки хардуерни системи и софтуер, като взаимодейства с тези регистрационни системи посредством технология с отворен стандарт за уебуслуги (XML, XSD, SOAP, WSDL, HTTP(s), Web services, WSS, X.509 и т.н.). |
3.2.9.
|
№ |
Описание |
|
54. |
Системата съответства на изискванията за защита на данните, изложени в Регламент (ЕО) № 45/2001 (членове 21, 22 и 23) и Директива 95/46/ЕО. |
|
55. |
Системата отговаря на стандартите на IDA. |
|
56. |
Системата поддържа UTF8. |
ГЛАВА 4: Оценяване
1. Процедура за оценяване съгласно член 20 (подготовка на решения в съответствие с член 25, параграф 2 от Решение 2008/615/ПВР)
1.1. Въпросник
Съответната работна група на Съвета съставя въпросник във връзка с всеки автоматизиран обмен на данни, както е посочено в глава 2 от Решение 2008/615/ПВР.
Държавата-членка попълва съответния въпросник веднага щом счете, че е изпълнила необходимите условия за дадена категория данни.
1.2. Пилотно изпитване
С цел оценяване на резултатите от въпросника държавата-членка, която желае да започне обмен на данни, провежда изпитване заедно с една или повече държави-членки, които вече обменят данни по решението на Съвета. Пилотното изпитване се провежда преди или скоро след посещението за оценка.
Условията и редът за пилотното изпитване ще се установят от съответната работна група на Съвета и ще се основават на предварителни, отделно сключени споразумения със съответната държава-членка. Държавите-членки, които участват в пилотното изпитване, ще вземат решение по отношение на практическите подробности.
1.3. Посещение за оценка
С цел оценяване на резултатите от въпросника се провежда посещение за оценка в държавата-членка, която желае да започне обмен на данни.
Условията и редът за провеждане на посещението ще се установят от съответната работна група и ще се основават на предварителни индивидуални споразумения със съответната държава-членка и екипа, който ще извърши оценката. Съответната държава-членка ще създаде условия на оценяващия екип да провери автоматизирания обмен на данни от категорията или категориите, които са предмет на оценката, по-специално като организира програмата за посещението съобразно изискванията на оценяващия екип.
В срок от един месец оценяващият екип ще изготви доклад за посещението за оценка и ще го изпрати на съответната държава-членка за коментар. Ако е уместно, оценяващият екип ще преработи този доклад въз основа на направените от държавата-членка коментари.
Оценяващият екип ще се състои от най-много трима експерти, определени от държавите-членки, участващи в автоматизирания обмен на данни за оценяваните категории данни, като тези експерти имат опит по отношение на въпросната категория данни, оправомощени са на национално равнище за работа с този вид данни и са проявили желание да участват в поне едно посещение за оценка в друга държава-членка. Комисията ще бъде поканена да се присъедини към оценяващия екип като наблюдател.
Членовете на оценяващия екип ще се съобразят с поверителния характер на информацията, която им стане известна по време на изпълнение на тази задача.
1.4. Докладване на Съвета
Съгласно член 25, параграф 2 от Решение 2008/615/ПВР, на Съвета се предоставя пълен доклад за оценката, в който са представени обобщено резултатите от въпросниците, посещението за оценка и пилотното изпитване.
2. Процедура за оценяване съгласно член 21
2.1. Статистика и доклад
Всяка държава-членка ще съставя статистика относно резултатите от автоматизирания обмен на данни. За да се осигури съпоставимост, моделът за съставяне на статистиката ще се определи от съответната работна група на Съвета.
Тази статистика ще се изпраща ежегодно на генералния секретариат, който ще изготвя обобщен преглед за изтеклата година, а също и на Комисията.
Освен това, от държавите-членки ще се изисква редовно, но не по-често от веднъж годишно, да подават информация за административните, техническите и финансовите аспекти на осъществявания автоматизиран обмен на данни, която е необходима за анализиране и усъвършенстване на процеса. Въз основа на тази информация ще бъде изготвен доклад за Съвета.
2.2. Преразглеждане
В разумен срок Съветът ще разгледа механизма за оценяване, който е описан тук, и ще го преработи както е необходимо.
3.
В рамките на съответната работна група на Съвета ще се провеждат редовни срещи на експерти с цел организирането и изпълнението на горепосочените процедури за оценяване, както и за обмен на опит и обсъждане на евентуални подобрения. При възможност, резултатите от обсъжданията на експертите ще се включват в доклада, посочен в точка 2.1 по-горе.
(1) „Изцяло обозначени“ означава, че е включено обработването на редки алелни стойности.
(2) Това е позицията съгласно определеното в ASCII-стандарта.
(3) M = задължително, когато са налице данни в националния регистър, O = незадължително.
(4) Всички атрибути, специално придадени от държавите-членки, се обозначават с Y.
(5) Хармонизирани съкращения за документите, вж. Директива 1999/37/ЕО на Съвета от 29 април 1999 г.
(6) M = задължително, когато са налице данни в националния регистър, O = незадължително.
(7) Хармонизирани съкращения за документите, вж. Директива 1999/37/ЕО на Съвета от 29 април 1999 г.
(8) В Люксембург се използват два различни вида документи за регистрация на превозно средство.
(9) M = задължително за използване или спазване, O = незадължително за използване или спазване.